
Java DB Developer's Guide
Version 10.5
Derby Document build:
August 10, 2009, 10:01:53 AM (EDT)

Apache License Version 2.0, January 2004 http://www.apache.org/licenses/ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. "License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. "Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. "Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License. "Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types. "Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below). "Derivative Works" shall mean any work, whether in Source or Object form, that is based on (or derived from) the Work and for which the editorial revisions, annotations, elaborations, or other modifications represent, as a whole, an original work of authorship. For the purposes of this License, Derivative Works shall not include works that remain separable from, or merely link (or bind by name) to the interfaces of, the Work and Derivative Works thereof. "Contribution" shall mean any work of authorship, including the original version of the Work and any modifications or additions to that Work or Derivative Works thereof, that is intentionally submitted to Licensor for inclusion in the Work by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Work, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution." "Contributor" shall mean Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Work. 2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare Derivative Works of, publicly display, publicly perform, sublicense, and distribute the Work and such Derivative Works in Source or Object form. 3. Grant of Patent License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Work or a Contribution incorporated within the Work constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for that Work shall terminate as of the date such litigation is filed. 4. Redistribution. You may reproduce and distribute copies of the Work or Derivative Works thereof in any medium, with or without modifications, and in Source or Object form, provided that You meet the following conditions: (a) You must give any other recipients of the Work or Derivative Works a copy of this License; and (b) You must cause any modified files to carry prominent notices stating that You changed the files; and (c) You must retain, in the Source form of any Derivative Works that You distribute, all copyright, patent, trademark, and attribution notices from the Source form of the Work, excluding those notices that do not pertain to any part of the Derivative Works; and (d) If the Work includes a "NOTICE" text file as part of its distribution, then any Derivative Works that You distribute must include a readable copy of the attribution notices contained within such NOTICE file, excluding those notices that do not pertain to any part of the Derivative Works, in at least one of the following places: within a NOTICE text file distributed as part of the Derivative Works; within the Source form or documentation, if provided along with the Derivative Works; or, within a display generated by the Derivative Works, if and wherever such third-party notices normally appear. The contents of the NOTICE file are for informational purposes only and do not modify the License. You may add Your own attribution notices within Derivative Works that You distribute, alongside or as an addendum to the NOTICE text from the Work, provided that such additional attribution notices cannot be construed as modifying the License. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of Your modifications, or for any such Derivative Works as a whole, provided Your use, reproduction, and distribution of the Work otherwise complies with the conditions stated in this License. 5. Submission of Contributions. Unless You explicitly state otherwise, any Contribution intentionally submitted for inclusion in the Work by You to the Licensor shall be under the terms and conditions of this License, without any additional terms or conditions. Notwithstanding the above, nothing herein shall supersede or modify the terms of any separate license agreement you may have executed with Licensor regarding such Contributions. 6. Trademarks. This License does not grant permission to use the trade names, trademarks, service marks, or product names of the Licensor, except as required for reasonable and customary use in describing the origin of the Work and reproducing the content of the NOTICE file. 7. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Work (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Work and assume any risks associated with Your exercise of permissions under this License. 8. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Work (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages. 9. Accepting Warranty or Additional Liability. While redistributing the Work or Derivative Works thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability. END OF TERMS AND CONDITIONS APPENDIX: How to apply the Apache License to your work. To apply the Apache License to your work, attach the following boilerplate notice, with the fields enclosed by brackets "[]" replaced with your own identifying information. (Don't include the brackets!) The text should be enclosed in the appropriate comment syntax for the file format. We also recommend that a file or class name and description of purpose be included on the same "printed page" as the copyright notice for easier identification within third-party archives. Copyright [yyyy] [name of copyright owner] Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
• | After installing Explains
the installation layout. | |
• | Upgrades Explains
how to upgrade a database created with a previous version of
Derby. | |
• | JDBC applications and Derby basics Basic
details for using Derby,
including loading the JDBC driver, specifying a database URL, starting Derby, and working with
Derby properties. | |
• | Deploying Derby applications An
overview of different deployment scenarios, and tips for getting the details
right when deploying applications. | |
• | Derby server-side programming Describes
how to program database-side JDBC routines, triggers, and table functions. | |
• | Controlling Derby application behavior JDBC, cursors, locking and isolation levels, and multiple connections. | |
• | Using Derby as a J2EE resource manager Information
for programmers developing back-end components in a J2EE system. | |
• | Derby and Security Describes
how to use the security features of
Derby. | |
• | Developing tools and using Derby with an IDE Tips
for tool designers. | |
• | SQL tips Insiders'
tricks of the trade for using SQL. | |
• | Localizing Derby An overview
of database localization. | |
• | Derby and standards Describes those parts of
Derby that are non-standard
or not typical for a database system. |
C:>echo %DERBY_HOME% C:\DERBY_HOME
• | index.html in the top-level directory is the top page for the on-line
documentation. | |||||||
• | RELEASE-NOTES.html, in the top-level Derby base
directory, contains important last-minute information. Read it first. | |||||||
• | /bin contains utilities and scripts for running Derby. | |||||||
• | /demo contains some sample applications, useful scripts, and prebuilt
databases.
| |||||||
• | /docs contains the on-line documentation (including this document). | |||||||
• | /javadoc contains the documented APIs for the public classes and
interfaces. Typically, you use the JDBC interface to interact with Derby;
however, you can use some of these additional classes in certain situations. | |||||||
• | /lib contains the Derby libraries. |
• | marks the database as upgraded to the current release (Version 10.5). | |
• | allows use of new features. |
1.
| Back up your database to a safe location using Derby online/offline
backup procedures. For more information on backup, see the Java DB Server and Administration Guide. | |
2.
| Update your CLASSPATH with the latest jar files. | |
3.
| Make sure that there are no older versions of the Derby jar
files in your CLASSPATH. You can determine if you have multiple versions of Derby in your CLASSPATH by using the sysinfo tool. To use the sysinfo tool,
execute the following command: The sysinfo tool uses information found in the Derby jar files to determine the version of any Derby jar in your CLASSPATH. Be sure that you have only one version of the Derby jar files specified in your CLASSPATH. |
• | Back up your database before you upgrade. | |
• | Ensure that only the new Derby jar
files are in your CLASSPATH. |
• | A full upgrade is a complete upgrade of the Derby database.
When you perform a full upgrade, you cannot connect to the database with an
older version of Derby and
you cannot revert back to the previous version. | |
• | A soft upgrade allows you to run a newer version of Derby against
an existing database without having to fully upgrade the database. This means
that you can continue to run an older version of Derby against
the database. However, if you perform a soft upgrade, certain features will
not be available to you until you perform a full upgrade. |
1.
| To upgrade the database, select the type of upgrade that you want
to perform:
|
Class.forName("org.apache.derby.jdbc.EmbeddedDriver");
java -Djdbc.drivers=org.apache.derby.jdbc.EmbeddedDriver applicationClass
• | you can specify the name of the database you want to connect to | |
• | you can specify a number of attributes and values that allow you to accomplish
tasks. For more information about what you can specify with the Derby connection
URL, see Database connection examples. |
jdbc:derby:[subsubprotocol:][databaseName][;attribute=value]*
• | directory: The default. Specify this explicitly only to distinguish
a database that might be ambiguous with one on the class path. | |
• | classpath: Databases are treated as read-only databases, and all databaseNames must
begin with at least a slash, because you specify them "relative" to the classpath
directory. See Accessing databases from the classpath for details. | |
• | jar: Databases are treated as read-only databases. DatabaseNames might
require a leading slash, because you specify them "relative" to the jar file.
See Accessing databases from a jar or zip file for details.
jar requires an additional element immediately before the
database name:
pathToArchive is the path to the jar or zip file that holds
the database. |
Connection conn = DriverManager.getConnection("jdbc:derby:sample");
2009-05-08 17:27:11.199 GMT: Booting Derby version The Apache Software Foundation - Apache Derby - 10.5.1.1 - (764942): instance a816c00e-0121-2140-ffd9-fffff0cfee85 on database directory C:\sampledb
DriverManager.getConnection("jdbc:derby:;shutdown=true");
2009-05-08 17:28:47.140 GMT: Shutting down instance a816c00e-0121-2140-ffd9-fffff0cfee85
Class.forName(org.apache.derby.jdbc.EmbeddedDriver).newInstance();
ERROR XJ040: Failed to start database 'sample', see the next exception for details. ERROR XSDB6: Another instance of Derby might have already booted the databaseC:\databases\sample.
WARNING: Derby (instance 80000000-00d2-3265-de92-000a0a0a0200) is attempting to boot the database /export/home/sky/wombat even though Derby (instance 80000000-00d2-3265-8abf-000a0a0a0200) might still be active. Only one instance of Derby should boot a database at a time. Severe and non-recoverable corruption can result and might have already occurred.
Sat Aug 14 09:42:51 PDT 2005: Booting Derby version Apache Derby - 10.0.0.1 - (29612): instance 80000000-00d2-1c87-7586-000a0a0b1300 on database at directory C:\tutorial_system\sample ------------------------------------------------------------ Sat Aug 14 09:42:59 PDT 2005: Booting Derby version Apache Derby - 10.0.0.1 - (29612): instance 80000000-00d2-1c87-9143-000a0a0b1300 on database at directory C:\tutorial_system\HelloWorldDB
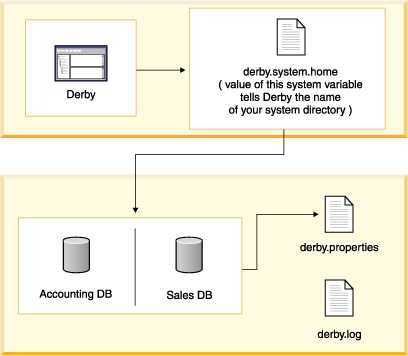
• | All databases exist within a system. | |
• | System-wide properties affect the entire system, and persistent system-wide
properties live in the system directory. | |
• | You can boot all the databases in the system, and the boot-up times of
all databases affect the performance of the system. | |
• | You can preboot databases only if they are within the system. (Databases
do not necessarily have to live inside the system directory, but keeping
your databases there is the recommended practice.) | |
• | Once you connect to a database, it is part of the current system and thus
inherits all system-wide properties. | |
• | Only one instance of Derby can
run in a JVM at a single time, and only one instance of Derby should
boot a database at one time. Keeping databases in the system directory makes
it less likely that you would use more than one instance of Derby. | |
• | The error log is located inside the system directory. |
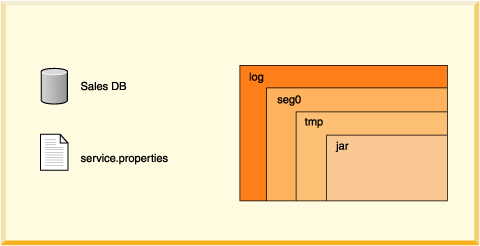
• | log directory Contains files that make up the database transaction
log, used internally for data recovery (not the same thing as the error log). | |
• | seg0 directory Contains one file for each user table, system
table, and index (known as conglomerates). | |
• | service.properties file A text file with internal configuration
information. | |
• | tmp directory (might not exist.) A temporary directory used
by Derby for large sorts
and deferred updates and deletes. Sorts are used by a variety of SQL statements.
For databases on read-only media, you might need to set a property to change
the location of this directory. See "Creating Derby Databases
for Read-Only Use". | |
• | jar directory (might not exist.) A directory in which jar files
are stored when you use database class loading. |
Type of Object | Limit |
tables in each database | java.lang.Long.MAX_VALUE Some operating systems
impose a limit to the number of files allowed in a single directory. |
indexes in each table | 32,767 or storage |
columns in each table | 1,012 |
number of columns on an index key | 16 |
rows in each table | No limit. |
size of table | No limit. Some operating systems impose a limit on the
size of a single file. |
size of row | No limit. Rows can span pages. Rows cannot span tables
so some operating systems impose a limit on the size of a single file, which
results in limiting the size of a table and size of a row in that table. |
jdbc:derby:myDB
Connection conn =DriverManager.getConnection("jdbc:derby:myDB");
jdbc:derby:../otherDirectory/myDB jdbc:derby:c:/otherDirectory/myDB
• | refer to a previously created Derby database | |
• | specify the create=true attribute |
jdbc:derby:directory:myDB
jdbc:derby:/sample
jdbc:derby:/demo/databases/sample
jdbc:derby:/jarDB1
jdbc:derby:jar:(c:/derby/lib/jar2.jar)jarDB2
• | jdbc:derby:db1 Open a connection to the database db1. db1 is
a directory located in the system directory. | |
• | jdbc:derby:london/sales Open a connection to the database london/sales. london is
a subdirectory of the system directory, and sales is a subdirectory
of the directory london. | |
• | jdbc:derby:/reference/phrases/french Open a connection to
the database /reference/phrases/french. On a UNIX system, this
would be the path of the directory. On a Windows system, the path would be C:\reference\phrases\french if
the current drive were C. If a jar file storing databases were in the
user's classpath, this could also be a path within the jar file. | |
• | jdbc:derby:a:/demo/sample Open a connection to the database
stored in the directory \demo\sample on drive A (usually the
floppy drive) on a Windows system. | |
• | jdbc:derby:c:/databases/salesdb
jdbc:derby:salesdb These two connection URLs connect to the same
database, salesdb, on a Windows platform if the system directory of
the Derby system is C:\databases. | |
• | jdbc:derby:support/bugsdb;create=true Create the database support/bugsdb in
the system directory, automatically creating the intermediate directory support if
it does not exist. | |
• | jdbc:derby:sample;shutdown=true Shut down the sample database.
(Authentication is not enabled, so no user credentials are required.)
| |
• | jdbc:derby:/myDB Access myDB (which is directly in
a directory in the classpath) as a read-only database. | |
• | jdbc:derby:classpath:/myDB Access myDB (which is directly
in a directory in the classpath) as a read-only database. The reason for using
the subsubprotocol is that it might have the same path as a database in the
directory structure. | |
• | jdbc:derby:jar:(C:/dbs.jar)products/boiledfood Access the
read-only database boiledfood in the products directory from
the jar file C:/dbs.jar. | |
• | jdbc:derby:directory:myDB Access myDB, which is in
the system directory. The reason for using the directory: subsubprotocol
is that it might happen to have the same path as a database in the classpath. |
jdbc:derby:;shutdown=true
// shutting down a database from your application DriverManager.getConnection( "jdbc:derby:sample;shutdown=true");
// shutting down an authenticated database as database owner DriverManager.getConnection( "jdbc:derby:securesample;user=joeowner;password=secret;shutdown=true");
jdbc:derby:databaseName;create=true
1.
| Specify the language and country codes for the territory attribute,
and the TERRITORY_BASED value for the collation attribute
when you create the database. For example:
|
1.
| Use the encryptionKey attribute in the connection URL. For example to create the database and encrypt the database encDB using
an external key, specify this URL:
Attention: If you lose the encryption key you
will not be able to boot the database. |
1.
| The attribute that you specify depends on how the database was
originally encrypted:
|
Class.forName("org.apache.derby.jdbc.EmbeddedDriver"); Properties p = new Properties(); p.setProperty("user", "sa"); p.setProperty("password", "manager"); p.setProperty("create", "true"); Connection conn = DriverManager.getConnection( "jdbc:derby:mynewDB", p);
Class.forName("org.apache.derby.jdbc.EmbeddedDriver").newInstance();
• | Whether to authorize users | |
• | Page size of tables and indexes | |
• | Where and whether to create an error log | |
• | Which databases in the system to boot |
• | system-wide Most properties can be set on a system-wide basis; that is, you set a
property for the entire system and all its databases and conglomerates, if this
is applicable. Some properties, such as error handling and automatic booting,
can be configured only in this way, since they apply to the entire system. (For
information about the Derby
system, see Derby system.) | |
• | database-wide Some properties can also be set on a database-wide basis. That is, the
property is true for the selected database only and not for the other databases
in the system unless it is set individually within each of them. |
• | That value is changed and the system is rebooted | |
• | The file is removed from the system and the system is rebooted | |
• | The database is booted outside of that system |
1.
| System-wide properties set programmatically (as a command-line option
to the JVM when starting the application or within application code) | |
2.
| Database-wide properties | |
3.
| System-wide properties set in the derby.properties file |
• | ||
• |
java -Dderby.system.home=C:\home\Derby\ -Dderby.storage.pageSize=8192 JDBCTest
Properties p = System.getProperties(); p.setProperty("derby.system.home", "C:\databases\sample");
• | Provide this file | |
• | Automatically create this file for you | |
• | Automatically write any properties or values to this file |
derby.infolog.append=true derby.storage.pageSize=8192 derby.storage.pageReservedSpace=60
Properties sprops = System.getProperties(); System.out.println("derby.storage.pageSize value: " + sprops.getProperty("derby.storage.pageSize"));
Type of property | How you set it | ||||||
System-wide |
| ||||||
Database-wide | Using system procedures and functions in an SQL statement |
• | As database-wide properties | |
• | As system-wide properties via a Properties object
in the application in which the Derby engine is embedded |
derby.storage.pageSize=8192
java -Dderby.system.home=c:\system_directory MyApp
CREATE TABLE table1 (a INT, b VARCHAR(10))
java -Dderby.system.home=c:\system_directory -Dderby.storage.pageSize=4096 MyApp CREATE TABLE anothertable (a INT, b VARCHAR(10))
CallableStatement cs = conn.prepareCall("CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY(?, ?)"); cs.setString(1, "derby.storage.pageSize"); cs.setString(2, "32768"); cs.execute(); cs.close();
CREATE TABLE table2 (a INT, b VARCHAR(10))
java -Dderby.system.home=c:\system_directory MyApp
CREATE TABLE table4 (a INT, b VARCHAR(10))
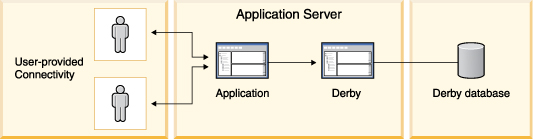
• | The Derby library (derby.jar). | |
• | The libraries for the application. You have the option of storing these
libraries in the database. | |
• | The database or databases used by the application, in the context of their
system directory. |
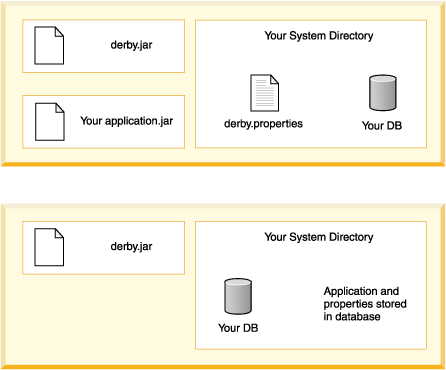
• | If you are setting any system-wide properties, see if they can be set
as database-wide properties instead. | |
• | Are any properties being set in the derby.properties file? Some
properties can only be set on a system-wide basis. If so, deploy the entire
system directory along with the properties file. Deploy only those databases
that you wish to include. Setting properties programmatically can simplify
this step- you will not have to worry about deploying the system directory/properties
file. |
1.
| Create and populate the database on read-write media. | |
2.
| Commit all transactions and shut down Derby in
the prescribed manner. If you do not shut down Derby in
the prescribed manner, Derby will
need to perform recovery the next time the system boots. Derby cannot
perform recovery on read-only media. | |
3.
| Delete the tmp directory if one was created within your
database directory. If you include this directory, Derby will
attempt to delete it and will return errors when attempting to boot a database
on read-only media. | |
4.
| For the read-only database, set the property derby.storage.tempDirectory to
a writable location. Derby needs
to write to temporary files for large sorts required by such SQL statements
as ORDER BY, UNION, DISTINCT, and GROUP BY. For more information about this
property, see the Java DB Reference Manual.
| |
5.
| Configure the database to send error messages to a writable file
or to an output stream. For information on the
derby.stream.error.file property, see the Java DB Reference Manual.
|
1.
| Move the database directory to the read-only media, including the
necessary subdirectory directories (log and seg0) and the file service.properties. | |
2.
| Use the database as usual, except that you will not be able to
insert or update any data in the database or create or drop dictionary objects. |
1.
| Create a database for use on read-only media. | |
2.
| From the directory that contains the database folder, archive the database
directory and its contents. For example, for the database sales that
lives in the system directory C:\london, issue the command from london.
Do not issue the command from inside the database directory itself. |
cd C:\london jar cMf C:\dbs.jar sales
cd C:\london jar cMf C:\dbs.jar sales products\boiledfood
jdbc:derby:jar:(pathToArchive)databasePathWithinArchive
jdbc:derby:jar:(C:/dbs.jar)products/boiledfood jdbc:derby:jar:(C:/dbs.jar)sales
jdbc:derby:jar:(C:/dbs.jar)/products/boiledfood
1.
| Set the classpath to include the jar or zip file before starting
up Derby:
| |
2.
| Connect to a database within the jar or zip file with one of the
following connection URLs:
|
jdbc:derby:classpath:/products/boiledfood
jdbc:derby:directory:databasePathInFileSystem
jdbc:derby:directory:/products/boiledfood
• | The standard Java packages (java.*, javax.*)
Derby does not prevent
you from storing such a jar file in the database, but these classes are
never loaded from the jar file. | |
• | The classes that are supplied with your Java environment (for example, sun.*) |
jar cf travelagent.jar travelagent/*.class.
• | Extract the required third-party classes from their jar file and include
only those classes in your jar file. Use this option when you need
only a small subset of the classes in the third-party jar file. | |
• | Store the third-party jar file in the database. Use this option
when you need most or all of the classes in the third-party jar file, since
your application and third-party logic can be upgraded separately. | |
• | Deploy the third-party jar file in the user's class path. Use
this option when the classes are already installed on a user's machine (for
example, Objectspace's JGL classes). |
• | Separate jar files with a colon (:). | |
• | Use two-part names for the jar files (schema name and jar name). Set the
property as a database-level property for the database. The first time you
set the property, you must reboot to load the classes. |
CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.classpath', 'APP.ToursLogic:APP.ACCOUNTINGLOGIC')
• | You originally configured database-level class loading for the
database correctly. Turning on the database-level class loading property requires
setting the derby.database.classpath property with
valid two-part names, then rebooting. | |
• | If changes to the derby.database.classpath property are needed
to reflect new jar files, you change the property to a valid value. |
• | to avoid blocking and deadlocks | |
• | to ensure that any updates done from within the routine are atomic with
the outer transaction |
Connection conn = DriverManager.getConnection( "jdbc:default:connection");
• | Can issue a commit or rollback only within a procedure (not a function).
| |
• | Cannot change the auto-commit connection attribute. | |
• | Cannot modify the data in a table used by the parent statement that called
the routine, using INSERT, UPDATE, or DELETE. For example, if a SELECT statement
using the T table calls the changeTables procedure, changeTables cannot
modify data in the T table. | |
• | Cannot drop a table used by the statement that called the routine. | |
• | Cannot be in a class whose static initializer executes DDL statements. |
CALL MYPROC()
try { preparedStatement.execute(); } catch (SQLException se ) { String SQLState = se.getSQLState(); if ( SQLState.equals( "23505" ) ) { correctDuplicateKey(); } else if ( SQLState.equals( "22003" ) ) { correctArithmeticOverflow(); } else { throw se; } }
CREATE TRIGGER . . . DELETE FROM flightavailability WHERE flight_id IN (SELECT flight_id FROM flightavailability WHERE YEAR(flight_date) < 2005);)
• | the "before" values of the rows being changed (their values before the
database event that caused the trigger to fire) | |
• | the "after" values of the rows being changed (the values to which the
database event is setting them) |
CREATE TRIGGER trig1 AFTER UPDATE ON flights REFERENCING OLD AS UPDATEDROW FOR EACH ROW MODE DB2SQL INSERT INTO flights_history VALUES (UPDATEDROW.FLIGHT_ID, UPDATEDROW.SEGMENT_NUMBER, UPDATEDROW.ORIG_AIRPORT, UPDATEDROW.DEPART_TIME, UPDATED ROW.DEST_AIRPORT, UPDATEDROW.ARRIVE_TIME, UPDATEDROW.MEAL, UPDATEDROW.FLYING_TIME, UPDATEDROW.MILES, UPDATEDROW.AIRCRAFT,'INSERTED FROM trig1');
• | XML-formatted reports and logs | |
• | Queries that run in foreign databases | |
• | Streaming data from sensors | |
• | RSS feeds |
• | next() | |
• | close() | |
• | wasNull() | |
• | getXXX() - When invoking a Derby-style table function at runtime, Derby calls a getXXX()
method on each referenced column. The particular getXXX()
method is based on the column's data type
as declared in the CREATE FUNCTION statement.
Preferred getXXX() methods for Derby-style table functions
explains how Derby selects an appropriate getXXX() method.
However, nothing prevents application code from calling other getXXX()
methods on the ResultSet. The returned ResultSet
needs to implement the getXXX() methods which Derby will call as well
as all getXXX() methods which the application will call.
|
public static ResultSet read() {...}
CREATE FUNCTION externalEmployees () RETURNS TABLE ( employeeId INT, lastName VARCHAR( 50 ), firstName VARCHAR( 50 ), birthday DATE ) LANGUAGE JAVA PARAMETER STYLE DERBY_JDBC_RESULT_SET READS SQL DATA EXTERNAL NAME 'com.acme.hrSchema.EmployeeTable.read'
INSERT INTO employees SELECT s.* FROM TABLE (externalEmployees() ) s;
Column Type Declared by CREATE FUNCTION | getXXX() Method Called by Derby for JDBC 3.0 and 4.0 | getXXX() Method Called by Derby for JSR 169 |
BIGINT | getLong() | Same |
BLOB | getBlob() | Same |
CHAR | getString() | Same |
CHAR FOR BIT DATA | getBytes() | Same |
CLOB | getClob() | Same |
DATE | getDate() | Same |
DECIMAL | getBigDecimal() | getString() |
DOUBLE | getDouble() | Same |
DOUBLE PRECISION | getDouble() | Same |
FLOAT | getDouble() | Same |
INTEGER | getInt() | Same |
LONG VARCHAR | getString() | Same |
LONG VARCHAR FOR BIT DATA | getBytes() | Same |
NUMERIC | getBigDecimal() | getString() |
REAL | getFloat() | Same |
SMALLINT | getShort() | Same |
TIME | getTime() | Same |
TIMESTAMP | getTimestamp() | Same |
VARCHAR | getString() | Same |
VARCHAR FOR BIT DATA | getBytes() | Same |
XML | Not supported | Not supported |
package com.acme.hrSchema; import java.sql.*; /** * Sample Table Function for reading the employee table in an * external database. */ public class EmployeeTable { public static ResultSet read() throws SQLException { Connection conn = getConnection(); PreparedStatement ps = conn.prepareStatement( "select * from hrSchema.EmployeeTable" ); return ps.executeQuery(); } protected static Connection getConnection() throws SQLException { String EXTERNAL_DRIVER = "com.mysql.jdbc.Driver"; try { Class.forName( EXTERNAL_DRIVER ); } catch (ClassNotFoundException e) { throw new SQLException( "Could not find class " + EXTERNAL_DRIVER ); } Connection conn = DriverManager.getConnection ( "jdbc:mysql://localhost/hr?user=root&password=mysql-passwd" ); return conn; } }
• | Expensive - It is expensive to create and loop through the
rows of the table function. This makes it likely that the optimizer will
place the table function in an outer slot of the join
order so that it will not be looped through often. | |
• | Repeatable - The table function can be instantiated
multiple times with the same results. This is probably true
for most table functions. However, some
table functions may open read-once streams. If the optimizer knows that a
table function is repeatable, then the optimizer can place
the table function in an inner slot where the function can be
invoked multiple times. If a table function is not
repeatable, then the optimizer must either place it in the
outermost slot or invoke the function once and store its contents in
a temporary table. |
• | No-arg constructor - The table function's class
must have a public constructor whose signature has no arguments. | ||||||||||||||||
• | VTICosting - The class must also implement
org.apache.derby.vti.VTICosting. This involves
implementing the following methods as described in
Measuring the cost of Derby-style table functions
and
Example VTICosting implementation:
|
• | C = The estimated Cost for creating and running the
table function. That is, the value returned by
VTICosting.getEstimatedCostPerInstantiation().
In general, Cost is a measure of time in milliseconds. | |
• | I = The optimizer's Imprecision. A measure of how skewed the optimizer's estimates tend
to be in your particular environment. See below for instructions on how to estimate this Imprecision. | |
• | A = The Actual time in milliseconds which it takes
to create and run this table function. |
• | O = The Optimizer's estimated cost for a plan. | |
• | T = The Total runtime in milliseconds for the plan. |
• | Select = Select all of the rows from a big table. | |
• | Record = In the statistics output, look for the ResultSet
which represents the table scan. That scan has a field
labelled "optimizer estimated cost". That's O. Now
look for the fields in that ResultSet's statistics labelled
"constructor time", "open time", "next time", and "close time". Add up
all of those fields. That total is T.
|
MAXIMUMDISPLAYWIDTH 7000; CALL SYSCS_UTIL.SYSCS_SET_RUNTIMESTATISTICS(1); CALL SYSCS_UTIL.SYSCS_SET_STATISTICS_TIMING(1); select * from T; values SYSCS_UTIL.SYSCS_GET_RUNTIMESTATISTICS();
• | P = The runtime spent Per row (in milliseconds). | |
• | N = The Number of rows in the table function. | |
• | E = The time spent creating an Empty instance of the
table function which has no rows in it. Usually, P * N dwarfs
E. That is, the table function instantiation cost is very
small compared to the actual cost of looping through the
rows. However, for some table functions, E may be significant
and may dominate the table function's cost when N is small. |
• | Short-circuit = Short-circuit the next() method of the
ResultSet
returned by your Derby-style Table Function so that it returns
false the first time it is called. This makes it
appear that the
ResultSet
has no rows.
| |
• | Select = Select all of the rows from the table function. | |
• | Record = In the statistics output, look for the VTIResultSet
which represents the table function scan. Add up
the values of the fields in that VTIResultSet's statistics labelled
"constructor time", "open time", "next time", and "close time".
That total is E.
|
• | Select = Select all of the rows from the table function. | |
• | Record = In the statistics output, look for the VTIResultSet
which represents the table function scan. Add up
the values of the fields in that VTIResultSet's statistics labelled
"constructor time", "open time", "next time", and "close
time". Subtract E from the result. Now divide by the
value of the field "Rows seen".
The result is P.
|
package com.acme.hrSchema; import java.io.Serializable; import java.sql.*; import org.apache.derby.vti.VTICosting; import org.apache.derby.vti.VTIEnvironment; /** * Tuned table function. */ public class TunedEmployeeTable extends EmployeeTable implements VTICosting { public TunedEmployeeTable() {} public double getEstimatedRowCount( VTIEnvironment optimizerState ) throws SQLException { return getRowCount( optimizerState ); } public double getEstimatedCostPerInstantiation( VTIEnvironment optimizerState ) throws SQLException { double I = 100.0; // optimizer imprecision double P = 10.0; // cost per row in milliseconds double E = 0.0; // cost of instantiating the external ResultSet double N = getRowCount( optimizerState ); return I * ( ( P * N ) + E ); } public boolean supportsMultipleInstantiations( VTIEnvironment optimizerState ) throws SQLException { return true; } ////////////////////////////////////////////////////////////////////////////// private double getRowCount( VTIEnvironment optimizerState ) throws SQLException { String ROW_COUNT_KEY = "rowCountKey"; Double estimatedRowCount = (Double) getSharedState( optimizerState, ROW_COUNT_KEY ); if ( estimatedRowCount == null ) { Connection conn = getConnection(); PreparedStatement ps = conn.prepareStatement( "select count(*) from hrSchema.EmployeeTable" ); ResultSet rs = ps.executeQuery(); rs.next(); estimatedRowCount = new Double( rs.getDouble( 1 ) ); setSharedState( optimizerState, ROW_COUNT_KEY, estimatedRowCount ); rs.close(); ps.close(); conn.close(); } return estimatedRowCount.doubleValue(); } private Serializable getSharedState( VTIEnvironment optimizerState, String key ) { return (Serializable) optimizerState.getSharedState( key ); } private void setSharedState( VTIEnvironment optimizerState, String key, Serializable value ) { optimizerState.setSharedState( key, value ); } }
Connection conn = DriverManager.getConnection( "jdbc:derby:sample"); System.out.println("Connected to database sample"); conn.setAutoCommit(false); Connection conn2 = DriverManager.getConnection( "jdbc:derby:newDB;create=true"); System.out.println("Created AND connected to newDB"); conn2.setAutoCommit(false); Connection conn3 = DriverManager.getConnection( "jdbc:derby:newDB"); System.out.println("Got second connection to newDB"); conn3.setAutoCommit(false);
• | Cursors You cannot use auto-commit if you do any positioned
updates or deletes (that is, an update or delete statement with a WHERE CURRENT
OF clause) on cursors which have the
ResultSet.CLOSE_CURSORS_AT_COMMIT holdability value
set. Auto-commit automatically closes cursors that are
explicitly opened with the
ResultSet.CLOSE_CURSORS_AT_COMMIT value, when you do any
in-place updates or deletes. An updatable cursor declared to be held
across commit (this is the default value) can execute updates and issue multiple
commits before closing the cursor. After an explicit or implicit commit, a
holdable forward-only cursor must be repositioned with a call to the
next method before it can accessed again. In this state,
the only other valid operation besides calling next is
calling close. | ||||||||||||||||||||||
• | Database-side JDBC routines (routines using nested connections) You cannot execute functions within SQL statements if those functions
perform a commit or rollback on the current connection. Since in auto-commit
mode all SQL statements are implicitly committed, Derby turns
off auto-commit during execution of database-side routines and turns it
back on when the statement completes. Routines that use nested connections
are not permitted to turn auto-commit on or off. | ||||||||||||||||||||||
• | Table-level locking and the SERIALIZABLE isolation level When
an application uses table-level locking and the SERIALIZABLE isolation level,
all statements that access tables hold at least shared table locks. Shared
locks prevent other transactions that update data from accessing the table.
A transaction holds a lock on a table until the transaction commits. So
even a SELECT statement holds a shared lock on a table until its connection
commits and a new transaction begins. Table 4. Summary
of Application Behavior with Auto-Commit On or Off
|
conn.setAutoCommit(false); // Autocommit must be off to use savepoints. Statement stmt = conn.createStatement(); int rows = stmt.executeUpdate("INSERT INTO TABLE1 (COL1) VALUES(1)"); // set savepoint Savepoint svpt1 = conn.setSavepoint("S1"); rows = stmt.executeUpdate("INSERT INTO TABLE1 (COL1) VALUES (2)"); ... conn.rollback(svpt1); ... conn.commit();
Connection conn = DriverManager.getConnection( "jdbc:derby:sample"); Statement s = conn.createStatement(); s.execute("set schema 'SAMP'"); //note that autocommit is on--it is on by default in JDBC ResultSet rs = s.executeQuery( "SELECT empno, firstnme, lastname, salary, bonus, comm " + "FROM samp.employee"); /** a standard JDBC ResultSet. It maintains a * cursor that points to the current row of data. The cursor * moves down one row each time the method next() is called. * You can scroll one way only--forward--with the next() * method. When auto-commit is on, after you reach the * last row the statement is considered completed * and the transaction is committed. */ System.out.println( "last name" + "," + "first name" + ": earnings"); /* here we are scrolling through the result set with the next() method.*/ while (rs.next()) { // processing the rows String firstnme = rs.getString("FIRSTNME"); String lastName = rs.getString("LASTNAME"); BigDecimal salary = rs.getBigDecimal("SALARY"); BigDecimal bonus = rs.getBigDecimal("BONUS"); BigDecimal comm = rs.getBigDecimal("COMM"); System.out.println( lastName + ", " + firstnme + ": " + (salary.add(bonus.add(comm)))); } rs.close(); // once we've iterated through the last row, // the transaction commits automatically and releases //shared locks s.close();
Statement stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_UPDATABLE); ResultSet uprs = stmt.executeQuery( "SELECT FIRSTNAME, LASTNAME, WORKDEPT, BONUS " + "FROM EMPLOYEE"); while (uprs.next()) { int newBonus = uprs.getInt("BONUS") + 100; uprs.updateInt("BONUS", newBonus); uprs.updateRow(); }
Statement stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_UPDATABLE); ResultSet uprs = stmt.executeQuery( "SELECT FIRSTNAME, LASTNAME, WORKDEPT, BONUS " + "FROM EMPLOYEE"); while (uprs.next()) { if (uprs.getInt("WORKDEPT")==300) { uprs.deleteRow(); } }
• | After an update or delete is made on a forward only result set,
the result set's cursor is no longer on the row just updated or
deleted, but immediately before the next row in the result set (it is
necessary to move to the next row before any further row operations
are allowed). This means that changes made by
ResultSet.updateRow() and
ResultSet.deleteRow() are never visible.
| |
• | If a row has been inserted, i.e using
ResultSet.insertRow() it may be visible in a forward
only result set. |
• | If the current row is deleted by a statement in the same transaction, calls to
ResultSet.updateRow() will cause an exception, since
the cursor is no longer positioned on a valid row. |
Statement stmt = conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE); ResultSet uprs = stmt.executeQuery( "SELECT FIRSTNAME, LASTNAME, WORKDEPT, BONUS " + "FROM EMPLOYEE"); uprs.absolute(5); // update the fifth row int newBonus = uprs.getInt("BONUS") + 100; uprs.updateInt("BONUS", newBonus); uprs.updateRow();
Statement stmt = conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE); ResultSet uprs = stmt.executeQuery( "SELECT FIRSTNAME, LASTNAME, WORKDEPT, BONUS " + "FROM EMPLOYEE"); uprs.last(); uprs.relative(-5); // moves to the 5th from the last row uprs.deleteRow();
• | Changes caused by other statements, triggers and other
transactions (others) are considered as other changes, and are not visible in
scrollable insensitive result sets. | |
• | Own updates and deletes are visible in Derby's scrollable
insensitive result sets. Note: Derby handles changes
made using positioned updates and deletes as own changes, so when made
via a result set's cursor such changes are also visible in that result
set.
| |
• | Rows inserted to the table may become visible in the result set. | |
• | ResultSet.rowDeleted() returns true if the row
has been deleted using the cursor or result set. It does not detect
deletes made by other statements or transactions. Note that the
method will also work for result sets with concurrency
CONCUR_READ_ONLY if the underlying result set is FOR UPDATE and a
cursor was used to delete the row.
| |
• | ResultSet.rowUpdated() returns true if the row
has been updated using the cursor or result set. It does not detect
updates made by other statements or transactions. Note that the
method will also work for result sets with concurrency
CONCUR_READ_ONLY if the underlying result set is FOR UPDATE and a
cursor was used to update the row.
| |
• | Note: Both ResultSet.rowUpdated() and
ResultSet.rowDeleted() return true if the row
first is updated and later deleted. |
• | The row has been deleted after it was read into the result set:
Scrollable insensitive result sets will give a warning with SQLState 01001 . | |
• | The table has been compressed: Scrollable insensitive
result sets will give a warning with SQLState
01001. A compress conflict may happen if the cursor is held
over a commit. This is because the table intent lock is released on
commit, and not reclaimed until the cursor moves to another row.
|
Statement stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_UPDATABLE); ResultSet uprs = stmt.executeQuery( "SELECT firstname, lastname, workdept, bonus " + "FROM employee"); uprs.moveToInsertRow(); uprs.updateString("FIRSTNAME", "Andreas"); uprs.updateString("LASTNAME", "Korneliussen"); uprs.updateInt("WORKDEPT", 123); uprs.insertRow(); uprs.moveToCurrentRow();
Statement s3 = conn.createStatement(); // name the statement so we can reference the result set // it generates s3.setCursorName("UPDATABLESTATEMENT"); // we will be able to use the following statement later // to access the current row of the cursor // a result set needs to be obtained prior to using the // WHERE CURRENT syntax ResultSet rs = s3.executeQuery("select * from FlightBookings FOR UPDATE of number_seats"); PreparedStatement ps2 = conn.prepareStatement( "UPDATE FlightBookings SET number_seats = ? " + "WHERE CURRENT OF UPDATABLESTATEMENT");
PreparedStatement ps2 = conn.prepareStatement( "UPDATE employee SET bonus = ? WHERE CURRENT OF "+ Updatable.getCursorName());
Connection conn = DriverManager.getConnection("jdbc:derby:sample"); conn.setAutoCommit(false); // Create the statement with concurrency mode CONCUR_UPDATABLE // to allow result sets to be updatable Statement stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_UPDATABLE, ResultSet.CLOSE_CURSORS_AT_COMMIT); // Updatable statements have some requirements // for example, select must be on a single table ResultSet uprs = stmt.executeQuery( "SELECT FIRSTNME, LASTNAME, WORKDEPT, BONUS " + "FROM EMPLOYEE FOR UPDATE of BONUS"); // Only bonus can be updated String theDept="E21"; while (uprs.next()) { String firstnme = uprs.getString("FIRSTNME"); String lastName = uprs.getString("LASTNAME"); String workDept = uprs.getString("WORKDEPT"); BigDecimal bonus = uprs.getBigDecimal("BONUS"); if (workDept.equals(theDept)) { // if the current row meets our criteria, // update the updatable column in the row uprs.updateBigDecimal("BONUS", bonus.add(BigDecimal.valueOf(250L))); uprs.updateRow(); System.out.println("Updating bonus for employee:" + firstnme + lastName); } } conn.commit(); // commit the transaction // close object uprs.close(); stmt.close(); // Close connection if the application does not need it any more conn.close();
//autocommit does not have to be off because even if //we accidentally scroll past the last row, the implicit commit //on the the statement will not close the result set because result sets //are held over commit by default conn.setAutoCommit(false); Statement s4 = conn.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_READ_ONLY); s4.execute("set schema 'SAMP'"); ResultSet scroller=s4.executeQuery( "SELECT sales_person, region, sales FROM sales " + "WHERE sales > 8 ORDER BY sales DESC"); if (scroller.first()) { // One row is now materialized System.out.println("The sales rep who sold the highest number" + " of sales is " + scroller.getString("SALES_PERSON")); } else { System.out.println("There are no rows."); } scroller.beforeFirst(); scroller.afterLast(); // By calling afterlast(), all rows will be materialized scroller.absolute(3); if (!scroller.isAfterLast()) { System.out.println("The employee with the third highest number " + "of sales is " + scroller.getString("SALES_PERSON") + ", with " + scroller.getInt("SALES") + " sales"); } if (scroller.isLast()) { System.out.println("There are only three rows."); } if (scroller.last()) { System.out.println("The least highest number " + "of sales of the top three sales is: " + scroller.getInt("SALES")); } scroller.close(); s4.close(); conn.commit() conn.close(); System.out.println("Closed connection");
• | CLOSE_CURSORS_AT_COMMIT Result sets are closed when an
implicit or explicit commit is performed. | |
• | HOLD_CURSORS_OVER_COMMIT Result sets are held open when
a commit is performed, implicitly or explicitly. This is the default behavior. |
• | Open result sets remain open. Non-scrollable result sets becomes
positioned before the next logical row of the result set. Scrollable
insensitive result sets keep their current position. | |||||||
• | When the session is terminated, the result set is closed and destroyed. | |||||||
• | All locks are released, including locks protecting the current
cursor position. | |||||||
• | For non-scrollable result sets, immediately following a commit, the
only valid operations that can be performed on the ResultSet
object are:
|
Isolation levels for JDBC | Isolation levels for SQL |
Connection.TRANSACTION_READ_UNCOMMITTED (ANSI level
0) | UR, DIRTY READ, READ UNCOMMITTED |
Connection.TRANSACTION_READ_COMMITTED (ANSI level
1) | CS, CURSOR STABILITY, READ COMMITTED |
Connection.TRANSACTION_REPEATABLE_READ (ANSI level
2) | RS |
Connection.TRANSACTION_SERIALIZABLE (ANSI level
3) | RR, REPEATABLE READ, SERIALIZABLE |
Anomaly | Example |
Dirty Reads A dirty read happens when a transaction
reads data that is being modified by another transaction that has not yet
committed. | Transaction A begins. Transaction B begins. (Transaction B sees data updated by transaction A. Those updates have not yet been committed.) |
Non-Repeatable Reads Non-repeatable reads happen when
a query returns data that would be different if the query were repeated within
the same transaction. Non-repeatable reads can occur when other transactions
are modifying data that a transaction is reading. | Transaction A begins. Transaction B begins. (Transaction B updates rows viewed by transaction A before transaction A commits.) If Transaction A issues the same SELECT statement, the results will be different. |
Phantom Reads Records that appear in a set being read
by another transaction. Phantom reads can occur when other transactions insert
rows that would satisfy the WHERE clause of another transaction's statement. | Transaction A begins. Transaction B begins. Transaction B inserts a row that would satisfy the query in Transaction A if it were issued again. |
Isolation Level | Table-Level Locking | Row-Level Locking |
TRANSACTION_READ_UNCOMMITTED | Dirty reads, nonrepeatable reads, and phantom reads possible | Dirty reads, nonrepeatable reads, and phantom reads possible |
TRANSACTION_READ_COMMITTED | Nonrepeatable reads and phantom reads possible | Nonrepeatable reads and phantom reads possible |
TRANSACTION_REPEATABLE_READ | Phantom reads not possible because entire table is locked | Phantom reads possible |
TRANSACTION_SERIALIZABLE | None | None |
• | TRANSACTION_SERIALIZABLE RR, SERIALIZABLE,
or REPEATABLE READ from SQL. TRANSACTION_SERIALIZABLE means
that Derby treats the transactions
as if they occurred serially (one after the other) instead of concurrently. Derby issues locks to prevent
all the transaction anomalies listed in Transaction Anomalies from
occurring. The type of lock it issues is sometimes called a range lock. | |||||||
• | TRANSACTION_REPEATABLE_READ RS from
SQL. TRANSACTION_REPEATABLE_READ means that Derby issues
locks to prevent only dirty reads and non-repeatable reads, but not phantoms.
It does not issue range locks for selects. | |||||||
• | TRANSACTION_READ_COMMITTED CS or CURSOR
STABILITY from SQL. TRANSACTION_READ_COMMITTED means
that Derby issues locks
to prevent only dirty reads, not all the transaction anomalies listed in Transaction Anomalies. TRANSACTION_READ_COMMITTED is
the default isolation level for transactions. | |||||||
• | TRANSACTION_READ_UNCOMMITTED UR, DIRTY
READ, or READ UNCOMMITTED from SQL. For a
SELECT INTO, FETCH with a read-only cursor, full select used in an INSERT,
full select/subquery in an UPDATE/DELETE, or scalar full select (wherever
used), READ UNCOMMITTED allows:
For other operations, the rules that apply to READ COMMITTED also
apply to READ UNCOMMITTED. |
' | Shared | Update | Exclusive |
Shared | + | + | - |
Update | + | - | - |
Exclusive | - | - | - |
• | For TRANSACTION_REPEATABLE_READ isolation, the locks are released at the
end of the transaction. | |
• | For TRANSACTION_READ_COMMITTED isolation, Derby locks
rows only as the application steps through the rows in the result. The current
row is locked. The row lock is released when the application goes to the next
row. | |
• | For TRANSACTION_SERIALIZABLE isolation, however, Derby locks
the whole set before the application begins stepping through. | |
• | For TRANSACTION_READ_UNCOMMITTED, no row locks are requested. |
• | For any isolation level, Derby locks all
the rows in the result plus an entire range of rows for updates or deletes. | |
• | For the TRANSACTION_SERIALIZABLE isolation level, Derby locks
all the rows in the result plus an entire range of rows in the table for SELECTs
to prevent nonrepeatable reads and phantoms. |
Transaction Isolation Level | Table-Level Locking | Row-Level Locking |
Connection.TRANSACTION_READ_UNCOMMITED (SQL: UR) | For SELECT statements, table-level locking is never requested
using this isolation level. For other statements, same as for TRANSACTION_READ_COMMITTED. | SELECT statements get no locks. For other statements, same
as for TRANSACTION_ READ_COMMITTED. |
Connection.TRANSACTION_READ_COMMITTED (SQL: CS) | SELECT statements get a shared lock on the entire table.
The locks are released when the user closes the ResultSet. Other statements
get exclusive locks on the entire table, which are released when the transaction
commits. | SELECTs lock and release single rows as the user steps
through the ResultSet. UPDATEs and DELETEs get exclusive locks on a
range of rows. INSERT statements get exclusive locks on single rows (and sometimes
on the preceding rows). |
Connection.TRANSACTION_REPEATABLE_READ (SQL: RS) | Same as for TRANSACTION_SERIALIZABLE | SELECT statements get shared locks on the rows that satisfy
the WHERE clause (but do not prevent inserts into this range). UPDATEs and
DELETEs get exclusive locks on a range of rows. INSERT statements get exclusive
locks on single rows (and sometimes on the preceding rows). |
Connection.TRANSACTION_SERIALIZABLE (SQL: RR) | SELECT statements get a shared lock on the entire table.
Other statements get exclusive locks on the entire table, which are released
when the transaction commits. | SELECT statements get shared locks on a range of rows.
UPDATE and DELETE statements get exclusive locks on a range of rows. INSERT
statements get exclusive locks on single rows (and sometimes on the preceding
rows). |
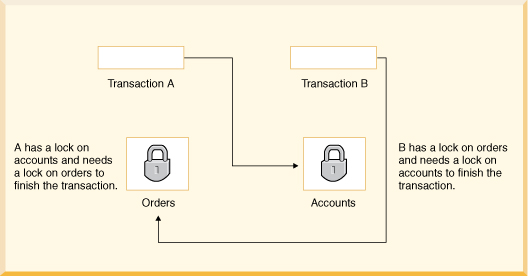
ERROR 40001: A lock could not be obtained due to a deadlock, cycle of locks & waiters is: Lock : ROW, DEPARTMENT, (1,14) Waiting XID : {752, X} , APP, update department set location='Boise' where deptno='E21' Granted XID : {758, X} Lock : ROW, EMPLOYEE, (2,8) Waiting XID : {758, U} , APP, update employee set bonus=150 where salary=23840 Granted XID : {752, X} The selected victim is XID : 752
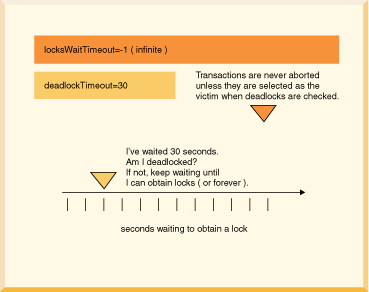
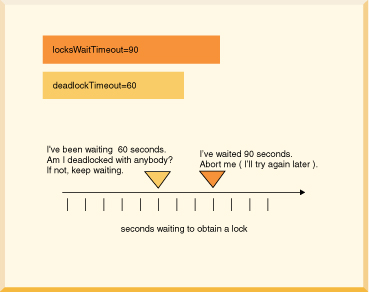
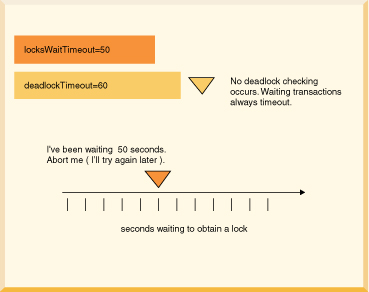
/// if this code might encounter a deadlock, // put the whole thing in a try/catch block // then try again if the deadlock victim exception // was thrown try { s6.executeUpdate( "UPDATE employee " + "SET bonus = 625 " "WHERE empno='000150'"); s6.executeUpdate("UPDATE project " + "SET respemp = '000150' " + "WHERE projno='IF1000'"); } // note: do not catch such exceptions in database-side methods; // catch such exceptions only at the outermost level of // application code. // See Database-side JDBC routines and SQLExceptions. catch (SQLException se) { if (se.getSQLState().equals("40001")) { // it was chosen as a victim of a deadlock. // try again at least once at this point. System.out.println( "Will try the transaction again."); s6.executeUpdate("UPDATE employee " + "SET bonus = 625 " + "WHERE empno='000150'"); s6.executeUpdate("UPDATE project " + "SET respemp = 000150 " + "WHERE projno='IF1000'"); } else throw se; }
• | Multiple applications access a single database (possible only when Derby is running inside a server
framework). | |||||||||||||
• | A single application has more than one Connection to the same database.
The way you deploy Derby affects
the ways applications can use multi-threading and connections, as shown in Threading and Connection Modes. Table 10. Threading and Connection Modes
|
• | Use the TRANSACTION_READ_COMMITTED isolation level and turn on
row-level locking (the defaults). | |
• | Beware of deadlocks caused by using more than one Connection in
a single thread (the most obvious case). For example, if the thread tries
to update the same table from two different Connections,
a deadlock can occur. | |
• | Assign Connections to threads that handle discrete tasks. For example,
do not have two threads update the Hotels table. Have one thread update
the Hotels table and a different one update the Groups table. | |
• | If threads access the same tables, commit transactions often. | |
• | Multi-threaded Java applications have the ability to self-deadlock without
even accessing a database, so beware of that too. | |
• | Use nested connections to share the same lock space. |
• | Committing or rolling back a transaction closes all open ResultSet objects
and currently executing Statements, unless you are using held cursors. If
one thread commits, it closes the Statements and ResultSets of
all other threads using the same connection. | |
• | Executing a Statement automatically closes any existing open ResultSet generated
by an earlier execution of that Statement. If threads share Statements,
one thread could close another's ResultSet. |
• | Avoid sharing Statements (and their ResultSets)
among threads. | |
• | Each time a thread executes a Statement, it should process the
results before relinquishing the Connection. | |
• | Each time a thread accesses the Connection, it should consistently
commit or not, depending on application protocol. | |
• | Have one thread be the "managing" database Connection thread that
should handle the higher-level tasks, such as establishing the Connection,
committing, rolling back, changing Connection properties
such as auto-commit, closing the Connection, shutting
down the database (in an embedded environment), and so on. | |
• | Close ResultSets and Statements that are
no longer needed in order to release resources. |
• | Use row-level locking. | |
• | Use the TRANSACTION_READ_COMMITTED isolation level. | |
• | Avoid queries that cannot use indexes; they require locking of all the
rows in the table (if only very briefly) and might block an update. |
PreparedStatement ps = conn.prepareStatement( "UPDATE account SET balance = balance + ? WHERE id = ?"); /* now assume two threads T1,T2 are given this java.sql.PreparedStatement object and that the following events happen in the order shown (pseudojava code)*/ T1 - ps.setBigDecimal(1, 100.00); T1 - ps.setLong(2, 1234); T2 - ps.setBigDecimal(1, -500.00); // *** At this point the prepared statement has the parameters // -500.00 and 1234 // T1 thinks it is adding 100.00 to account 1234 but actually // it is subtracting 500.00 T1 - ps.executeUpdate(); T2 - ps.setLong(2, 5678); // T2 executes the correct update T2 - ps.executeUpdate(); /* Also, the auto-commit mode of the connection can lead to some strange behavior.*/
catch (Throwable e) { System.out.println("exception thrown:"); errorPrint(e); } static void errorPrint(Throwable e) { if (e instanceof SQLException) SQLExceptionPrint((SQLException)e); else System.out.println("A non-SQL error: " + e.toString()); } static void SQLExceptionPrint(SQLException sqle) { while (sqle != null) { System.out.println("\n---SQLException Caught---\n"); System.out.println("SQLState: " + (sqle).getSQLState()); System.out.println("Severity: " + (sqle).getErrorCode()); System.out.println("Message: " + (sqle).getMessage()); sqle.printStackTrace(); sqle = sqle.getNextException(); } }
• | org.apache.derby.jdbc.EmbeddedDataSource
and org.apache.derby.jdbc.EmbeddedDataSource40 Implements the javax.sql.DataSource interface,
which a JNDI server can reference. Typically this is the object that you work
with as a DataSource. | |
• | org.apache.derby.jdbc.EmbeddedConnectionPoolDataSource
and org.apache.derby.jdbc.EmbeddedConnectionPoolDataSource40 Implements the javax.sql.ConnectionPoolDataSource interface.
A factory for PooledConnection objects. | |
• | org.apache.derby.jdbc.EmbeddedXADataSource
and org.apache.derby.jdbc.EmbeddedXADataSource40 Derby's
implementation of the javax.sql.XADataSource interface. |
// If your application is running on the Java SE 6 platform, // and if you would like to call DataSource methods specific // to the JDBC 4 API (for example, isWrapperFor), use the // JDBC 4 variants of these classes: // // org.apache.derby.jdbc.EmbeddedConnectionPoolDataSource40 // org.apache.derby.jdbc.EmbeddedDataSource40 // org.apache.derby.jdbc.EmbeddedXADataSource40 // import org.apache.derby.jdbc.EmbeddedConnectionPoolDataSource; import org.apache.derby.jdbc.EmbeddedDataSource; import org.apache.derby.jdbc.EmbeddedXADataSource; javax.sql.ConnectionPoolDataSource cpds = new EmbeddedConnectionPoolDataSource(); javax.sql.DataSource ds = new EmbeddedDataSource(); javax.sql.XADataSource xads = new EmbeddedXADataSource();
• | DatabaseName This mandatory property must be set. It identifies
which database to access. To access a database named wombat located at
/local1/db/wombat, call setDatabaseName("/local1/db/wombat")
on the data source object. | |
• | CreateDatabase Optional. Sets a property to create a database
the next time the getConnection method of a data source object is called.
The string createString is always "create" (or possibly null). (Use
the method setDatabaseName() to define the name of
the database.) | |
• | ShutdownDatabase Optional. Sets a property to shut down a
database. The string shutDownString is always "shutdown" (or possibly
null). Shuts down the database the next time the getConnection method
of a data source object is called. | |
• | DataSourceName Optional. Name for ConnectionPoolDataSource
or XADataSource. Not used by the data source object. Used for informational
purposes only. | |
• | Description Optional. Description of the data source. Not
used by the data source object. Used for informational purposes only. | |
• | connectionAttributes Optional. Connection attributes specific
to Derby. See the Java DB Reference Manual for a more information about
the attributes. |
javax.sql.XADataSource xads = makeXADataSource(mydb, true); // example of setting property directory using // Derby 's XADataSource object import org.apache.derby.jdbc.EmbeddedXADataSource; import javax.sql.XADataSource; // dbname is the database name // if create is true, create the database if not already created XADataSource makeXADataSource (String dbname, boolean create) { // // If your application runs on JDK 1.6 or higher, then // you will use the JDBC4 variant of this class: // EmbeddedXADataSource40. // EmbeddedXADataSource xads = new EmbeddedXADataSource(); // use Derby 's setDatabaseName call xads.setDatabaseName(dbname); if (create) xads.setCreateDatabase("create"); return xads; }
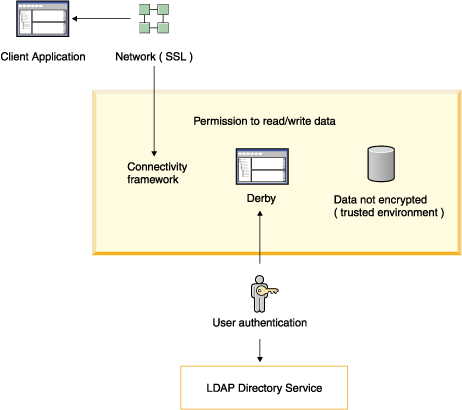
• | User authentication Derby verifies
user names and passwords before permitting them access to the Derby system. | |
• | User authorization A means of granting specific users permission
to read a database or to write to a database. | |
• | Disk encryption A means of encrypting Derby data
stored on disk. | |
• | Validation of Certificate for Signed Jar Files In a Java 2
environment, Derby validates
certificates for classes loaded from signed jar files. | |
• | Network encryption and authentication Derby
network traffic may be encrypted with SSL/TLS. SSL/TLS certificate
authentication is also supported. See "Network encryption and authentication with SSL/TLS" in the
Java DB Server and Administration Guide for
details. |
1.
| When first working with security, work with system-level properties only
so that you can easily override them if you make a mistake. | |
2.
| Be sure to create at least one valid user, and grant that user full (read-write)
access. For example, you might always want to create a user called sa with
the password derby while
you are developing. | |
3.
| Test the authentication system while it is still configured at the system
level. Be absolutely certain that you have configured the system correctly
before setting the properties as database-level properties. | |
4.
| Before disabling system-level properties (by setting derby.database.propertiesOnly to
true), test that at least one database-level read-write user (such as sa)
is valid. If you do not have at least one valid user that the system can authenticate,
you will not be able to access your database. |
1.
| Configure security features as system properties. See
Scope of properties and
Setting system-wide properties. | |
2.
| Provide administrative-level protection for the derby.properties file
and Derby databases. For
example, you can protect these files and directories with operating system
permissions and firewalls. | |
3.
| Turn on user authentication for your system. All users must provide
valid user IDs and passwords to access the Derby system.
If you are using Derby's
built-in users, configure users for the system in the derby.properties file.
Provide the protection for this file. | |
4.
| Configure user authorization for sensitive databases in your system.
Only designated users will be able to access sensitive databases. You typically
configure user authorization with database-level properties. It is also possible
to configure user authorization with system-level properties. This is useful
when you are developing systems or when all databases have the same level
of sensitivity. | |
5.
| Check and if necessary configure your Derby network security
according to your environment. See the section "Network client security" in the
Java DB Server and Administration Guide. |
1.
| Encrypt the database when you create it. | |
2.
| Configure all security features as database-level properties.
These properties are stored in the database (which is encrypted). See
Scope of properties and
Setting database-wide properties for more
information. | |
3.
| Turn on protection for database-level properties so that they cannot
be overridden by system properties by setting the derby.database.propertiesOnly property
to TRUE. See the Java DB Reference Manual for details
on this property. | |
4.
| To prevent unauthorized users from accessing databases once they
are booted, turn on user authentication for the database and configure user
authorization for the database. | |
5.
| If you are using Derby's
built-in users, configure each user as a database-level property so that user
names and passwords can be encrypted. |
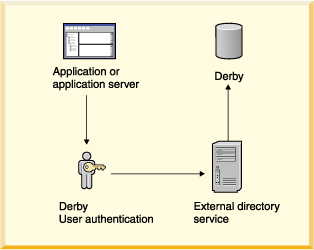
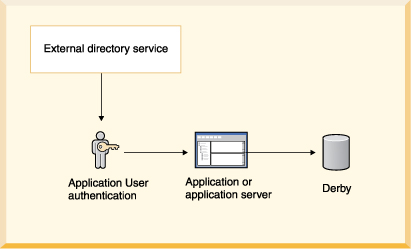
• | External directory service: LDAP directory service.
This includes Windows NT domain user authentication through the Netscape NT
Synchronization Service. | |
• | ||
• |
• | Netscape Directory Server Netscape Directory Server is an LDAP directory
server. In addition, the Netscape Directory Synchronization Service synchronizes
entries in a Windows NT directory with the entries in Netscape's Directory
Server. It allows you to use the Windows NT directory as a repository for Derby users. | |
• | UMich slapd (freeware for the UNIX platform from the University of Michigan) | |
• | AE SLAPD for Windows NT, from AEInc |
• | derby.authentication.server Set the property derby.authentication.server to
the URL to the LDAP server. For example:
The LDAP server may be specified using just the server name, the server name
and its port number separated by a colon, or a ldap URL. If a full URL is not provided,
Derby will by default use unencrypted LDAP - to use SSL encrypted LDAP an URL
starting with "ldaps://" must be provided. Also note that support for ldaps:// URLs requires that Derby runs on Java 1.4.2 or higher. |
cn=mary,ou=People,o=FlyTours.com uid=mary,ou=People,o=FlyTours.com
• | You have set derby.authentication.ldap.searchFilter to derby.user. | |
• | A user DN has been cached locally for the specific user with the derby.user.UserName property. |
• | derby.authentication.ldap.searchAuthDN (optional) Specifies
the DN with which to bind (authenticate) to the server when searching for
user DNs. This parameter is optional if anonymous access is supported by your
server. If specified, this value must be a DN recognized by the directory
service, and it must also have the authority to search for the entries. If
not set, it defaults to an anonymous search using the root DN specified by
the derby.authentication.ldap.searchBase property. For example:
| |
• | derby.authentication.ldap.searchAuthPW (optional) Specifies
the password to use for the guest user configured above to bind to the directory
service when looking up the DN. If not set, it defaults to an anonymous search
using the root DN specified by the derby.authentication.ldap.searchBase property.
| |
• | derby.authentication.ldap.searchBase (optional) Specifies
the root DN of the point in your hierarchy from which to begin a guest search
for the user's DN. For example:
When
using Netscape Directory Server, set this property to the root DN, the special
entry to which access control does not apply (optional). |
• | derby.authentication.ldap.searchFilter (optional) Set derby.authentication.ldap.searchFilter to
a logical expression that specifies what constitutes a user for your LDAP
directory service. The default value of this property is objectClass=inetOrgPerson.
For example:
|
import org.apache.derby.authentication.UserAuthenticator; import java.io.FileInputStream; import java.util.Properties; import java.sql.SQLException; /** * A simple example of a specialized Authentication scheme. * The system property 'derby.connection.requireAuthentication' * must be set * to true and 'derby.authentication.provider' must * contain the full class name of the overriden authentication * scheme, i.e., the name of this class. * * @see org.apache.derby.authentication.UserAuthenticator */ public class MyAuthenticationSchemeImpl implements UserAuthenticator { private static final String USERS_CONFIG_FILE = "myUsers.cfg"; private static Properties usersConfig; // Constructor // We get passed some Users properties if the //authentication service could not set them as //part of System properties. // public MyAuthenticationSchemeImpl() { } /* static block where we load the users definition from a users configuration file.*/ static { /* load users config file as Java properties File must be in the same directory where Derby gets started. (otherwise full path must be specified) */ FileInputStream in = null; usersConfig = new Properties(); try { in = new FileInputStream(USERS_CONFIG_FILE); usersConfig.load(in); in.close(); } catch (java.io.IOException ie) { // No Config file. Raise error message System.err.println( "WARNING: Error during Users Config file retrieval"); System.err.println("Exception: " + ie); } } /** * Authenticate the passed-in user's credentials. * A more complex class could make calls * to any external users directory. * * @param userName The user's name * @param userPassword The user's password * @param databaseName The database * @param infoAdditional jdbc connection info. * @exception SQLException on failure */ public boolean authenticateUser(String userName, String userPassword, String databaseName, Properties info) throws SQLException { /* Specific Authentication scheme logic. If user has been authenticated, then simply return. If user name and/or password are invalid, then raise the appropriate exception. This example allows only users defined in the users config properties object. Check if the passed-in user has been defined for the system. We expect to find and match the property corresponding to the credentials passed in. */ if (userName == null) // We do not tolerate 'guest' user for now. return false; // // Check if user exists in our users config (file) // properties set. // If we did not find the user in the users config set, then // try to find if the user is defined as a System property. // String actualUserPassword; actualUserPassword = usersConfig.getProperty(userName); if (actualUserPassword == null) actualUserPassword = System.getProperty(userName); if (actualUserPassword == null) // no such passed-in user found return false; // check if the password matches if (!actualUserPassword.equals(userPassword)) return false; // Now, check if the user is a valid user of the database if (databaseName != null) { /* if database users restriction lists present, then check if there is one for this database and if so, check if the user is a valid one of that database. For this example, the only user we authorize in database DarkSide is user 'DarthVader'. This is the only database users restriction list we have for this example. We authorize any valid (login) user to access the OTHER databases in the system. Note that database users ACLs could be set in the same properties file or a separate one and implemented as you wish. */ // if (databaseName.equals("DarkSide")) { // check if user is a valid one. if (!userName.equals("DarthVader")) // This user is not a valid one of the passed-in return false; } } // The user is a valid one in this database return true; } }
derby.authentication.provider=BUILTIN
derby.user."FRed"=java
-- adding the user sa with password 'derbypass' CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.user.sa', 'derbypass') -- adding the user mary with password 'little7xylamb' CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.user.mary', 'little7xylamb') -- removing mary by setting password to null CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.user.mary', null)
# Users definition # derby.user.sa=derbypass derby.user.mary=little7xylamb
Property Name | Use |
derby.connection.requireAuthentication | Turns on user authentication. |
derby.authentication.provider | Specifies the kind of user authentication to use. |
derby.authentication.server | For LDAP user authentication, specifies the location of
the server. |
derby.authentication.ldap.searchAuthDN, derby.authentication.ldap.searchAuthPW,
derby.authentication.ldap.searchFilter, and derby.authentication.ldap.searchBase | Configures the way that DN searches are performed. |
derby.user.UserName | Creates a user name and password for the built-in user
repository inDerby. |
java.naming.* | JNDI properties. See Appendix A in the JNDI API reference
for more information about these properties. |
• | Separately as arguments to the following signature of the method: getConnection(String
url, String user, String password)
| |
• | As attributes to the database connection URL
| |
• | By setting the user and password properties in a Properties object as
with other connection URL attributes
|
• | Within the user authentication system, Fred is known as FRed. Your
external user authorization service is case-sensitive, so Fred must always
type his name that way.
| |
• | Within the Derby user
authorization system, Fred becomes a case-insensitive authorization identifier.
Fred is known as FRED. | |
• | When specifying which users are authorized to access the accounting database,
you must list Fred's authorization identifier, FRED (which you can
type as FRED, FREd, or fred, since the system automatically
converts it to all-uppercase).
|
• | Within the user authentication system, Fred is known as Fred!.
You must now put double quotes around the name, because it is not a valid SQL92Identifier.
(Derby knows to remove
the double quotes when passing the name to the external authentication system.)
| |
• | Within the Derby user
authorization system, Fred becomes a case-sensitive authorization identifier.
Fred is known as Fred!. | |
• | When specifying which users are authorized to access the accounting database,
you must list Fred's authorization identifier, "Fred!" (which you must
always delimit with double quotation marks).
|
• | The derby.database.defaultConnectionMode property controls
the default access mode. Use the derby.database.defaultConnectionMode property
to specify the default connection access that users have when they connect
to the database. If you do not explicitly set the derby.database.defaultConnectionMode property,
the default user authorization for a database is fullAccess,
which is read-write access. | |
• | The derby.database.fullAccessUsers and derby.database.readOnlyAccessUsers properties
are user specific properties. Use these properties to specify the user IDs
that have read-write access and read-only access to a database. | |
• | The derby.database.sqlAuthorization property enables
SQL standard authorization. Use the derby.database.sqlAuthorization property
to specify if object owners can grant and revoke permission for users to perform
SQL actions on database objects. The default setting for the derby.database.sqlAuthorization property
is FALSE. When the derby.database.sqlAuthorization property
is set to TRUE, object owners can use the GRANT and REVOKE
SQL statements to set the user permissions for specific database objects or
for specific SQL actions. |
• | When the derby.database.sqlAuthorization property is FALSE,
the ability to read from or write to database objects is determined by the
setting for the derby.database.defaultConnectionMode property.
If the derby.database.defaultConnectionMode property is set
to readOnlyAccess, users can access all of the database
objects but they cannot update or drop the objects. | |
• | When the derby.database.sqlAuthorization property is TRUE,
the ability to read from or write to database objects is further restricted
to the owner of the database objects. The owner must grant permission for
others to access the database objects. No one but the owner of an object or
the
database owner
can drop the object. | |
• | The access mode specified for the derby.database.defaultConnectionMode property
overrides the permissions that are granted by the owner of a database object.
For example, if a user is granted INSERT privileges on a table but the user
only has read-only connection authorization, the user cannot insert data into
the table. |
• | noAccess | |
• | readOnlyAccess | |
• | fullAccess |
CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.fullAccessUsers', 'sa') CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.defaultConnectionMode', 'readOnlyAccess')
CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.fullAccessUsers', 'Fred') CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.defaultConnectionMode', 'noAccess')
CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.fullAccessUsers', 'sa,maria')
CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.readOnlyAccessUsers', 'guest,Fred')
CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.fullAccessUsers', '"Elena!"')
Action | Read-only access | Full access |
Executing SELECT statements | X | X |
Reading database properties | X | X |
Loading database classes from jar files | X | X |
Executing INSERT, UPDATE, or DELETE statements | X | |
Executing DDL statements | X | |
Adding or replacing jar files | X | |
Setting database properties | X |
• | TRUE | |
• | FALSE |
derby.database.sqlAuthorization=true
CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.sqlAuthorization', 'true')
• | DELETE | |
• | EXECUTE | |
• | INSERT | |
• | SELECT | |
• | REFERENCES | |
• | TRIGGER | |
• | UPDATE |
User anita needs the following permissions to create the view:CREATE VIEW s.v(vc1,vc2,vc3) AS SELECT t1.c1,t1.c2,f(t1.c3) FROM t1 JOIN t2 ON t1.c1 = t2.c1 WHERE t2.c2 = 5
• | Ownership of the schema s, so that she can create something
in the schema | |
• | Ownership of the table t1, so that she can allow others
to see columns in the table | |
• | SELECT permission on column t2.c1 and column t2.c2 | |
• | EXECUTE permission on function f |
create role reader; create role updater; create role taskLeaderA; create role taskLeaderB; create role projectLeader; grant reader to updater; grant updater to taskLeaderA; grant updater to taskLeaderB; grant taskLeaderA to projectLeader; grant taskLeaderB to projectLeader;
reader | v updater / \ taskLeaderA taskLeaderB \ / projectLeader
grant projectLeader to updater;
SET ROLE taskLeaderA;
• | The privilege is granted directly to the current user | |
• | The privilege is granted to PUBLIC | |
• | The privilege is also granted to another role B in the current role's set of
contained roles | |
• | The session's current user is the database owner or the object owner |
• | CREATE ROLE statement | |
• | SET ROLE statement | |
• | DROP ROLE statement | |
• | GRANT statement | |
• | REVOKE statement | |
• | CURRENT_ROLE function | |
• | SYSCS_DIAG.CONTAINED_ROLES table function | |
• | SYSROLES system table |
• | You cannot create a role if you are not the database owner. An attempt to do
so raises the SQLException 4251A. | |
• | You cannot create a role if a role with that name already exists. An attempt
to do so raises the SQLException X0Y68. | |
• | You cannot create a role name if there is a user by that name. An attempt to
create a role name that conflicts with an existing user name raises the
SQLException X0Y68. | |
• | A role name cannot start with the prefix SYS (after case normalization). Use
of the prefix SYS raises the SQLException 4293A. | |
• | You cannot create a role with the name PUBLIC (after case normalization).
PUBLIC is a reserved authorization identifier. An attempt to create a role with
the name PUBLIC raises SQLException 4251B. |
• | You cannot drop a role if you are not the database owner. An attempt to do
so raises the SQLException 4251A. | |
• | You cannot drop a role that does not exist. An attempt to do so raises the
SQLException 0P000. |
• | You cannot set a role if you are not the database owner. An attempt to do so
raises the SQLException 4251A. | |
• | You cannot set a role that does not exist. An attempt to do so raises the
SQLException 0P000. | |
• | You cannot set a role when a transaction is in progress. An attempt to do so
raises the SQLException 25001. | |
• | You cannot use NONE or a malformed identifier as a string or
? argument to SET ROLE. An attempt to do so raises the
SQLException XCXA0. |
• | You cannot grant a role if you are not the database owner. An attempt to do
so raises the SQLException 4251A. | |
• | You cannot grant a role that does not exist. An attempt to do so raises the
SQLException 0P000. | |
• | You cannot grant the role "PUBLIC". An attempt to do so raises the
SQLException 4251B. | |
• | You cannot grant a role if doing so would create a circularity by granting
a container role to a contained role. An attempt to do so raises the
SQLException 4251C. |
• | You cannot revoke a role if you are not the database owner. An attempt to do
so raises the SQLException 4251A. | |
• | You cannot revoke a role that does not exist. An attempt to do so raises the
SQLException 0P000. | |
• | You cannot revoke the role "PUBLIC". An attempt to do so raises the
SQLException 4251B. |
• | For J2SE/J2EE 1.4 or higher, the JRE's provider is the default. | |
• | If your environment for some reason does not include a provider, it must be specified. |
• | If the database is configured with log archival, you must disable log
archival and perform a shutdown before you can encrypt the database. | |
• | If there are any global transaction that are in the prepared state after
recovery, the database cannot be encrypted. |
1.
| Specify the dataEncryption=true attribute and either the encryptionKey attribute
or the bootPassword attribute in a URL and boot the database. For example, to encrypt the salesdb database with
the boot password abc1234xyz, specify the following attributes
in the URL:
If authentication
and
SQL authorization
are both enabled, the credentials of the
database owner
must be supplied as well, since encryption is a restricted operation.
If you disabled log archival before you encrypted the database, create
a new backup of the database after the database is encrypted. |
• | AES (128, 192, and 256 bits) | |
• | DES (the default) (56 bits) | |
• | DESede (168 bits) | |
• | All other algorithms (128 bits) |
jdbc:derby:encryptionDB1;create=true;dataEncryption=true; bootPassword=clo760uds2caPe
-- using the the provider library jce_jdk13-10b4.zip| -- available from www.bouncycastle.org jdbc:derby:encryptedDB3;create=true;dataEncryption=true; bootPassword=clo760uds2caPe; encryptionProvider=org.bouncycastle.jce.provider.BouncyCastleProvider; encryptionAlgorithm=DES/CBC/NoPadding -- using a provider -- available from -- http://jcewww.iaik.tu-graz.ac.at/download.html jdbc:derby:encryptedDB3;create=true;dataEncryption=true; bootPassword=clo760uds2caPe; encryptionProvider=iaik.security.provider.IAIK;encryptionAlgorithm= DES/CBC/NoPadding
• | DES (the default) | |||||||||||||||||||
• | DESede (also known as triple DES) | |||||||||||||||||||
• | Any encryption algorithm that fulfills the following requirements:
For example, the algorithm Blowfish implemented in the Sun
JCE package fulfills these requirements. |
algorithmName/feedbackMode/padding
• | CBC | |
• | CFB | |
• | ECB | |
• | OFB |
jdbc:derby:encdbcbc_192;create=true;dataEncryption=true; encryptionKeyLength=192;encryptionAlgorithm=AES/CBC/NoPadding; bootPassword=Thursday
1.
| Use the type of encryption that is currently used to encrypt the
database:
If authentication
and
SQL authorization
are both enabled, the credentials of the
database owner
must be supplied, since reencryption is a restricted operation.
|
• | If the database is configured with log archival for roll-forward recovery,
you must disable log archival and perform a shutdown before you can encrypt
the database with a new boot password. | |
• | If there are any global transaction that are in the prepared state after
recovery, the database cannot be encrypted with a new boot password. | |
• | If the database is currently encrypted with an external encryption key,
you should use the newEncryptionKey attribute
to encrypt the database. |
1.
| Specify the newBootPassword attribute in a URL and reboot
the database. For example, when the following URL is used when
the salesdb database is rebooted, the database is encrypted
with the new encryption key, and is protected by the password new1234xyz:
If authentication
and
SQL authorization
are both enabled, the credentials of the
database owner
must be supplied as well, since reencryption is a restricted operation.
If you disabled log archival before you applied the new boot
password, create a new backup of the database after the database is reconfigured
with the new boot password. |
• | If the database is configured with log archival for roll-forward recovery,
you must disable log archival and perform a shutdown before you can encrypt
the database with a new external encryption key. | |
• | If there are any global transaction that are in the prepared state after
recovery, the database cannot be encrypted with a new encryption key. | |
• | If the database is currently encrypted with a boot password , you should
use the newBootPassword attribute
to encrypt the database. |
1.
| Specify the newEncryptionKey attribute in a URL and reboot
the database. For example, when the following URL is used when
the salesdb database is rebooted, the database is encrypted
with the new encryption key 6862636465666768:
If authentication
and
SQL authorization
are both enabled, the credentials of the
database owner
must be supplied as well, since encryption is a restricted operation.
If you disabled log archival before you applied the new encryption
key, create a new backup of the database after the database is reconfigured
with new the encryption key.
|
jdbc:derby:wombat;bootPassword=clo760uds2caPe
jdbc:derby:flintstone;encryptionAlgorithm=AES/CBC/NoPadding; encryptionKey=c566bab9ee8b62a5ddb4d9229224c678
• | The first connection to the database in the JVM session | |
• | The first connection to the database after the database has been explicitly
shut down | |
• | The first connection to the database after the system has been shut down
and then rebooted |
• | If the class is signed, Derby will:
|
• | JVM subversion, running the application under a home-grown JVM. | |
• | Trolling for objects | |
• | Class substitution, locating a class that has access to sensitive data
and replacing it with one that passes on information |
# turn on user authentication derby.connection.requireAuthentication=true # set the authentication provider to an external LDAP server derby.authentication.provider=LDAP # the host name and port number of the LDAP server derby.authentication.server=godfrey:389 # the search base for user names derby.authentication.ldap.searchBase=o=oakland.mycompany.com # explicitly show the access mode for databases (this is default) derby.database.defaultConnectionMode=fullAccess
CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.defaultConnectionMode', 'noAccess') CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.fullAccessUsers', 'prez,cfo,numberCruncher') CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.readOnlyAccessUsers', 'clerk1,clerk2')
1.
| Creates a database named authClientDB, using the client
driver. | |
2.
| Sets database properties that create users with different levels of access
(read-only and full access), require authentication, and set the default access
level to no access. | |
3.
| Closes the connection and shuts down the database. |
1.
| Tries to connect to the database without a username and password, raising
an exception. | |
2.
| Connects to the database as a user with read-only access; the connection
succeeds, but an attempt to create a table raises an exception. | |
3.
| Connects to the database as a user with full access; this user can create
and populate a table. | |
4.
| Removes the table. | |
5.
| Closes the connection and shuts down the database. |
import java.sql.*; public class AuthExampleClient1 { public static void main(String[] args) { String driver = "org.apache.derby.jdbc.ClientDriver"; String dbName="authClientDB"; String connectionURL = "jdbc:derby://localhost:1527/" + dbName + ";create=true"; Connection conn = null; // Load the driver. This code is not needed if you are using // JDK 6, because in that environment the driver is loaded // automatically when the application requests a connection. try { Class.forName(driver); System.out.println(driver + " loaded."); } catch (java.lang.ClassNotFoundException ce) { System.err.print("ClassNotFoundException: "); System.err.println(ce.getMessage()); System.out.println("\n Make sure your CLASSPATH variable " + "contains %DERBY_HOME%\\lib\\derbyclient.jar " + "(${DERBY_HOME}/lib/derbyclient.jar).\n"); } catch (Exception ee) { errorPrintAndExit(ee); } // Create and boot the database and set up users, then shut down // the database as one of the users with full access try { System.out.println("Trying to connect to " + connectionURL); conn = DriverManager.getConnection(connectionURL); System.out.println("Connected to database " + connectionURL); turnOnBuiltInUsers(conn); // Close connection conn.close(); System.out.println("Closed connection"); /* Shut down the database to make static properties take * effect. Because the default connection mode is now * noAccess, you must specify a user that has access. But * because requireAuthentication does not take effect until * you restart the database, the password is not checked. * * Database shutdown throws the 08006 exception to confirm * success. */ try { DriverManager.getConnection( "jdbc:derby://localhost:1527/" + dbName + ";user=sa;password=badpass;shutdown=true"); } catch (SQLException se) { if ( !se.getSQLState().equals("08006") ) { throw se; } } System.out.println("Database shut down normally"); } catch (Throwable e) { errorPrintAndExit(e); } } /** * Turn on built-in user authentication and user authorization. * * @param conn a connection to the database. */ public static void turnOnBuiltInUsers(Connection conn) throws SQLException { String setProperty = "CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY("; String getProperty = "VALUES SYSCS_UTIL.SYSCS_GET_DATABASE_PROPERTY("; String requireAuth = "'derby.connection.requireAuthentication'"; String defaultConnMode = "'derby.database.defaultConnectionMode'"; String fullAccessUsers = "'derby.database.fullAccessUsers'"; String readOnlyAccessUsers = "'derby.database.readOnlyAccessUsers'"; String provider = "'derby.authentication.provider'"; String propertiesOnly = "'derby.database.propertiesOnly'"; System.out.println("Turning on authentication."); Statement s = conn.createStatement(); // Set and confirm requireAuthentication s.executeUpdate(setProperty + requireAuth + ", 'true')"); ResultSet rs = s.executeQuery(getProperty + requireAuth + ")"); rs.next(); System.out.println("Value of requireAuthentication is " + rs.getString(1)); // Set authentication scheme to Derby builtin s.executeUpdate(setProperty + provider + ", 'BUILTIN')"); // Create some sample users s.executeUpdate( setProperty + "'derby.user.sa', 'ajaxj3x9')"); s.executeUpdate( setProperty + "'derby.user.guest', 'java5w6x')"); s.executeUpdate( setProperty + "'derby.user.mary', 'little7xylamb')"); // Define noAccess as default connection mode s.executeUpdate( setProperty + defaultConnMode + ", 'noAccess')"); // Confirm default connection mode rs = s.executeQuery(getProperty + defaultConnMode + ")"); rs.next(); System.out.println("Value of defaultConnectionMode is " + rs.getString(1)); // Define read-write users s.executeUpdate( setProperty + fullAccessUsers + ", 'sa,mary')"); // Define read-only user s.executeUpdate( setProperty + readOnlyAccessUsers + ", 'guest')"); // Confirm full-access users rs = s.executeQuery(getProperty + fullAccessUsers + ")"); rs.next(); System.out.println( "Value of fullAccessUsers is " + rs.getString(1)); // Confirm read-only users rs = s.executeQuery(getProperty + readOnlyAccessUsers + ")"); rs.next(); System.out.println( "Value of readOnlyAccessUsers is " + rs.getString(1)); // We would set the following property to TRUE only when we were // ready to deploy. Setting it to FALSE means that we can always // override using system properties if we accidentally paint // ourselves into a corner. s.executeUpdate("CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY(" + "'derby.database.propertiesOnly', 'false')"); s.close(); } /** * Report exceptions, with special handling of SQLExceptions, * and exit. * * @param e an exception (Throwable) */ static void errorPrintAndExit(Throwable e) { if (e instanceof SQLException) SQLExceptionPrint((SQLException)e); else { System.out.println("A non-SQL error occurred."); e.printStackTrace(); } System.exit(1); } /** * Iterate through a stack of SQLExceptions. * * @param sqle a SQLException */ static void SQLExceptionPrint(SQLException sqle) { while (sqle != null) { System.out.println("\n---SQLException Caught---\n"); System.out.println("SQLState: " + (sqle).getSQLState()); System.out.println("Severity: " + (sqle).getErrorCode()); System.out.println("Message: " + (sqle).getMessage()); sqle = sqle.getNextException(); } } }
import java.sql.*; public class AuthExampleClient2 { public static void main(String[] args) { String driver = "org.apache.derby.jdbc.ClientDriver"; String dbName="authClientDB"; String connectionURL = "jdbc:derby://localhost:1527/" + dbName; Connection conn = null; // Restart database and confirm that unauthorized users cannot // access it // Load the driver. This code is not needed if you are using // JDK 6, because in that environment the driver is loaded // automatically when the application requests a connection. try { Class.forName(driver); System.out.println(driver + " loaded."); } catch (java.lang.ClassNotFoundException ce) { System.err.print("ClassNotFoundException: "); System.err.println(ce.getMessage()); System.out.println("\n Make sure your CLASSPATH variable " + "contains %DERBY_HOME%\\lib\\derbyclient.jar " + "(${DERBY_HOME}/lib/derbyclient.jar). \n"); } catch (Exception ee) { errorPrintAndExit(ee); } // Try to log in with no username or password try { // connection attempt should fail System.out.println("Trying to connect to " + connectionURL + " without username or password"); conn = DriverManager.getConnection(connectionURL); System.out.println( "ERROR: Unexpectedly connected to database " + dbName); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("08004")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); } else { errorPrintAndExit(e); } } // Log in as a user with read-only access try { // connection should succeed, but create table should fail String newURL = connectionURL + ";user=guest;password=java5w6x"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName + " with read-only access"); Statement s = conn.createStatement(); s.executeUpdate("CREATE TABLE t1(C1 VARCHAR(6))"); System.out.println( "ERROR: Unexpectedly allowed to modify database " + dbName); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("25503")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); try { conn.close(); } catch (SQLException ee) { errorPrintAndExit(ee); } } else { errorPrintAndExit(e); } } // Log in as a user with full access // Create, update, and query table try { // this should succeed String newURL = connectionURL + ";user=mary;password=little7xylamb"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName); Statement s = conn.createStatement(); s.executeUpdate("CREATE TABLE T1(C1 VARCHAR(6))"); System.out.println("Created table T1"); s.executeUpdate("INSERT INTO T1 VALUES('hello')"); ResultSet rs = s.executeQuery("SELECT * FROM T1"); rs.next(); System.out.println("Value of T1/C1 is " + rs.getString(1)); s.executeUpdate("DROP TABLE T1"); s.close(); } catch (SQLException e) { errorPrintAndExit(e); } try { cleanUpAndShutDown(conn); } catch (SQLException e) { errorPrintAndExit(e); } } /** * Close connection and shut down database. * * @param conn a connection to the database */ public static void cleanUpAndShutDown (Connection conn) throws SQLException { String dbName="authClientDB"; String connectionURL = "jdbc:derby://localhost:1527/" + dbName; try { conn.close(); System.out.println("Closed connection"); // As mary, shut down the database. try { String newURL = connectionURL + ";user=mary;password=little7xylamb;shutdown=true"; DriverManager.getConnection(newURL); } catch (SQLException se) { if ( !se.getSQLState().equals("08006") ) { throw se; } } System.out.println("Database shut down normally"); } catch (SQLException e) { errorPrintAndExit(e); } } /** * Report exceptions, with special handling of SQLExceptions, * and exit. * * @param e an exception (Throwable) */ static void errorPrintAndExit(Throwable e) { if (e instanceof SQLException) SQLExceptionPrint((SQLException)e); else { System.out.println("A non-SQL error occurred."); e.printStackTrace(); } System.exit(1); } /** * Iterate through a stack of SQLExceptions. * * @param sqle a SQLException */ static void SQLExceptionPrint(SQLException sqle) { while (sqle != null) { System.out.println("\n---SQLException Caught---\n"); System.out.println("SQLState: " + (sqle).getSQLState()); System.out.println("Severity: " + (sqle).getErrorCode()); System.out.println("Message: " + (sqle).getMessage()); sqle = sqle.getNextException(); } } }
CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.connection.requireAuthentication', 'true') CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.authentication.provider', 'BUILTIN') CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.user.redbaron', 'red29PlaNe') CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY( 'derby.database.propertiesOnly', true')
1.
| Starts Derby and creates
a database named authEmbDB, using the embedded driver. | |
2.
| Sets database properties that create users with different levels of access
(read-only and full access), require authentication, and set the default access
level to no access. | |
3.
| Closes the connection, then stops and restarts the database so that the
authentication changes can take effect. | |
4.
| Tries to connect to the database without a username and password, raising
an exception. | |
5.
| Connects to the database as a user with read-only access; the connection
succeeds, but an attempt to create a table raises an exception. | |
6.
| Connects to the database as a user with full access; this user can create
and populate a table. | |
7.
| Deletes the table. | |
8.
| Closes the connection, shuts down the database, then shuts down
Derby. |
import java.sql.*; public class AuthExampleEmbedded { public static void main(String[] args) { String driver = "org.apache.derby.jdbc.EmbeddedDriver"; String dbName="authEmbDB"; String connectionURL = "jdbc:derby:" + dbName + ";create=true"; Connection conn = null; // Load the driver. This code is not needed if you are using // JDK 6, because in that environment the driver is loaded // automatically when the application requests a connection. try { Class.forName(driver); System.out.println(driver + " loaded."); } catch (java.lang.ClassNotFoundException ce) { System.err.print("ClassNotFoundException: "); System.err.println(ce.getMessage()); System.out.println("\n Make sure your CLASSPATH variable " + "contains %DERBY_HOME%\\lib\\derby.jar " + "(${DERBY_HOME}/lib/derby.jar).\n"); } catch (Exception ee) { errorPrintAndExit(ee); } // Create and boot the database and set up users, then shut down // the database as one of the users with full access try { System.out.println("Trying to connect to " + connectionURL); conn = DriverManager.getConnection(connectionURL); System.out.println("Connected to database " + connectionURL); turnOnBuiltInUsers(conn); // close the connection conn.close(); System.out.println("Closed connection"); /* Shut down the database to make static properties take * effect. Because the default connection mode is now * noAccess, you must specify a user that has access. But * because requireAuthentication does not take effect until * you restart the database, the password is not checked. * * Database shutdown throws the 08006 exception to confirm * success. */ try { DriverManager.getConnection("jdbc:derby:" + dbName + ";user=sa;password=badpass;shutdown=true"); } catch (SQLException se) { if ( !se.getSQLState().equals("08006") ) { throw se; } } System.out.println("Database shut down normally"); } catch (SQLException e) { errorPrintAndExit(e); } // Restart database and confirm that unauthorized users cannot // access it connectionURL = "jdbc:derby:" + dbName; // Try to log in with no username or password try { // connection attempt should fail System.out.println("Trying to connect to " + connectionURL + " without username or password"); conn = DriverManager.getConnection(connectionURL); System.out.println( "ERROR: Unexpectedly connected to database " + dbName); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("08004")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); } else { errorPrintAndExit(e); } } // Log in as a user with read-only access try { // connection should succeed, but create table should fail String newURL = connectionURL + ";user=guest;password=java5w6x"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName + " with read-only access"); Statement s = conn.createStatement(); s.executeUpdate("CREATE TABLE t1(C1 VARCHAR(6))"); System.out.println( "ERROR: Unexpectedly allowed to modify database " + dbName); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("25503")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); try { conn.close(); } catch (SQLException ee) { errorPrintAndExit(ee); } } else { errorPrintAndExit(e); } } // Log in as a user with full access // Create, update, and query table try { // this should succeed String newURL = connectionURL + ";user=mary;password=little7xylamb"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName); Statement s = conn.createStatement(); s.executeUpdate("CREATE TABLE T1(C1 VARCHAR(6))"); System.out.println("Created table T1"); s.executeUpdate("INSERT INTO T1 VALUES('hello')"); ResultSet rs = s.executeQuery("SELECT * FROM T1"); rs.next(); System.out.println("Value of T1/C1 is " + rs.getString(1)); s.executeUpdate("DROP TABLE T1"); s.close(); } catch (SQLException e) { errorPrintAndExit(e); } try { cleanUpAndShutDown(conn); } catch (SQLException e) { errorPrintAndExit(e); } } /** * Close connection and shut down database. Since this is embedded * mode, we must also shut down the Derby system. * * @param conn a connection to the database */ public static void cleanUpAndShutDown (Connection conn) throws SQLException { String dbName="authEmbDB"; String connectionURL = "jdbc:derby:" + dbName; try { conn.close(); System.out.println("Closed connection"); // As mary, shut down the database. try { String newURL = connectionURL + ";user=mary;password=little7xylamb;shutdown=true"; DriverManager.getConnection(newURL); } catch (SQLException se) { if ( !se.getSQLState().equals("08006") ) { throw se; } } System.out.println("Database shut down normally"); try { DriverManager.getConnection("jdbc:derby:;shutdown=true"); } catch (SQLException se) { if ( !se.getSQLState().equals("XJ015") ) { throw se; } } System.out.println("Derby system shut down normally"); } catch (SQLException e) { errorPrintAndExit(e); } } /** * Turn on built-in user authentication and user authorization. * * @param conn a connection to the database */ public static void turnOnBuiltInUsers(Connection conn) throws SQLException { String setProperty = "CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY("; String getProperty = "VALUES SYSCS_UTIL.SYSCS_GET_DATABASE_PROPERTY("; String requireAuth = "'derby.connection.requireAuthentication'"; String defaultConnMode = "'derby.database.defaultConnectionMode'"; String fullAccessUsers = "'derby.database.fullAccessUsers'"; String readOnlyAccessUsers = "'derby.database.readOnlyAccessUsers'"; String provider = "'derby.authentication.provider'"; String propertiesOnly = "'derby.database.propertiesOnly'"; System.out.println("Turning on authentication."); Statement s = conn.createStatement(); // Set and confirm requireAuthentication s.executeUpdate(setProperty + requireAuth + ", 'true')"); ResultSet rs = s.executeQuery(getProperty + requireAuth + ")"); rs.next(); System.out.println("Value of requireAuthentication is " + rs.getString(1)); // Set authentication scheme to Derby builtin s.executeUpdate(setProperty + provider + ", 'BUILTIN')"); // Create some sample users s.executeUpdate( setProperty + "'derby.user.sa', 'ajaxj3x9')"); s.executeUpdate( setProperty + "'derby.user.guest', 'java5w6x')"); s.executeUpdate( setProperty + "'derby.user.mary', 'little7xylamb')"); // Define noAccess as default connection mode s.executeUpdate( setProperty + defaultConnMode + ", 'noAccess')"); // Confirm default connection mode rs = s.executeQuery(getProperty + defaultConnMode + ")"); rs.next(); System.out.println("Value of defaultConnectionMode is " + rs.getString(1)); // Define read-write user s.executeUpdate( setProperty + fullAccessUsers + ", 'sa,mary')"); // Define read-only user s.executeUpdate( setProperty + readOnlyAccessUsers + ", 'guest')"); // Confirm full-access users rs = s.executeQuery(getProperty + fullAccessUsers + ")"); rs.next(); System.out.println( "Value of fullAccessUsers is " + rs.getString(1)); // Confirm read-only users rs = s.executeQuery(getProperty + readOnlyAccessUsers + ")"); rs.next(); System.out.println( "Value of readOnlyAccessUsers is " + rs.getString(1)); // We would set the following property to TRUE only when we were // ready to deploy. Setting it to FALSE means that we can always // override using system properties if we accidentally paint // ourselves into a corner. s.executeUpdate(setProperty + propertiesOnly + ", 'false')"); s.close(); } /** * Report exceptions, with special handling of SQLExceptions, * and exit. * * @param e an exception (Throwable) */ static void errorPrintAndExit(Throwable e) { if (e instanceof SQLException) SQLExceptionPrint((SQLException)e); else { System.out.println("A non-SQL error occurred."); e.printStackTrace(); } System.exit(1); } /** * Iterate through a stack of SQLExceptions. * * @param sqle a SQLException */ static void SQLExceptionPrint(SQLException sqle) { while (sqle != null) { System.out.println("\n---SQLException Caught---\n"); System.out.println("SQLState: " + (sqle).getSQLState()); System.out.println("Severity: " + (sqle).getErrorCode()); System.out.println("Message: " + (sqle).getMessage()); sqle = sqle.getNextException(); } } }
1.
| Creates a database named sqlAuthClientDB, using the client
driver. The connection URL creates the database as the user
mary, who is therefore the database owner. After SQL
authorization is enabled, only the database owner will have the right to set and
read database properties. | |
2.
| Sets database properties that create users with different levels of access
(no access, read-only access, and full access), that require authentication, and
that turn on SQL authorization. The users mary and
sqlsam have full access. | |
3.
| Closes the connection, then shuts down the database so that the
authentication and SQL authorization changes can take effect. |
1.
| Tries to connect to the database without a username and password, raising
an exception. | |
2.
| Tries to connect to the database as a user with no access, raising an
exception. | |
3.
| Connects to the database as a user with read-only access; the connection
succeeds, but an attempt to create a table raises an exception. | |
4.
| Connects to the database as mary, who has full access; this
user creates and populates a table. This user also grants select and insert
privileges on this table to another user. | |
5.
| Connects to the database as sqlsam, the user who has been
granted select and insert privileges by mary. This user has
full (that is, read-write) access on the connection level, but has limited
powers for this table because SQL authorization is active. The user successfully
performs select and insert operations on the table, but an attempt to delete a
row from the table raises an exception. | |
6.
| Connects to the database again as mary, who then deletes
the table. | |
7.
| Shuts down the database. |
import java.sql.*; public class AuthExampleClientSQLAuth1 { public static void main(String[] args) { String driver = "org.apache.derby.jdbc.ClientDriver"; String dbName="sqlAuthClientDB"; String dbOwner="mary"; String connectionURL = "jdbc:derby://localhost:1527/" + dbName + ";user=" + dbOwner + ";create=true"; Connection conn = null; // Load the driver. This code is not needed if you are using // JDK 6, because in that environment the driver is loaded // automatically when the application requests a connection. try { Class.forName(driver); System.out.println(driver + " loaded."); } catch (java.lang.ClassNotFoundException ce) { System.err.print("ClassNotFoundException: "); System.err.println(ce.getMessage()); System.out.println("\n Make sure your CLASSPATH variable " + "contains %DERBY_HOME%\\lib\\derbyclient.jar " + "(${DERBY_HOME}/lib/derbyclient.jar).\n"); } catch (Exception ee) { errorPrintAndExit(ee); } // Create and boot the database as user mary (who then becomes // the database owner), set up users and then shut down the // database try { System.out.println("Trying to connect to " + connectionURL); conn = DriverManager.getConnection(connectionURL); System.out.println("Connected to database " + connectionURL); turnOnBuiltInUsers(conn); // Close connection conn.close(); System.out.println("Closed connection"); /* Shut down the database to make static properties take * effect. Because the default connection mode is now * noAccess, you must specify a user that has access. But * because requireAuthentication and sqlAuthorization do not * take effect until you restart the database, you do not * need to specify a password. * * Database shutdown throws the 08006 exception to confirm * success. */ try { DriverManager.getConnection( "jdbc:derby://localhost:1527/" + dbName + ";user=mary;shutdown=true"); } catch (SQLException se) { if ( !se.getSQLState().equals("08006") ) { throw se; } } System.out.println("Database shut down normally"); } catch (Throwable e) { errorPrintAndExit(e); } } /** * Turn on built-in user authentication and SQL authorization. * * Default connection mode is fullAccess, but SQL authorization * restricts access to the owners of database objects. * * @param conn a connection to the database */ public static void turnOnBuiltInUsers(Connection conn) throws SQLException { String setProperty = "CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY("; String getProperty = "VALUES SYSCS_UTIL.SYSCS_GET_DATABASE_PROPERTY("; String requireAuth = "'derby.connection.requireAuthentication'"; String sqlAuthorization = "'derby.database.sqlAuthorization'"; String defaultConnMode = "'derby.database.defaultConnectionMode'"; String fullAccessUsers = "'derby.database.fullAccessUsers'"; String readOnlyAccessUsers = "'derby.database.readOnlyAccessUsers'"; String provider = "'derby.authentication.provider'"; String propertiesOnly = "'derby.database.propertiesOnly'"; System.out.println( "Turning on authentication and SQL authorization."); Statement s = conn.createStatement(); // Set requireAuthentication s.executeUpdate(setProperty + requireAuth + ", 'true')"); // Set sqlAuthorization s.executeUpdate(setProperty + sqlAuthorization + ", 'true')"); // Retrieve and display property values ResultSet rs = s.executeQuery(getProperty + requireAuth + ")"); rs.next(); System.out.println( "Value of requireAuthentication is " + rs.getString(1)); rs = s.executeQuery(getProperty + sqlAuthorization + ")"); rs.next(); System.out.println( "Value of sqlAuthorization is " + rs.getString(1)); // Set authentication scheme to Derby builtin s.executeUpdate(setProperty + provider + ", 'BUILTIN')"); // Create some sample users s.executeUpdate( setProperty + "'derby.user.sa', 'ajaxj3x9')"); s.executeUpdate( setProperty + "'derby.user.guest', 'java5w6x')"); s.executeUpdate( setProperty + "'derby.user.mary', 'little7xylamb')"); s.executeUpdate( setProperty + "'derby.user.sqlsam', 'light8q9bulb')"); // Define noAccess as default connection mode s.executeUpdate( setProperty + defaultConnMode + ", 'noAccess')"); // Confirm default connection mode rs = s.executeQuery(getProperty + defaultConnMode + ")"); rs.next(); System.out.println("Value of defaultConnectionMode is " + rs.getString(1)); // Define read-write users s.executeUpdate( setProperty + fullAccessUsers + ", 'sqlsam,mary')"); // Define read-only user s.executeUpdate( setProperty + readOnlyAccessUsers + ", 'guest')"); // Therefore, user sa has no access // Confirm full-access users rs = s.executeQuery(getProperty + fullAccessUsers + ")"); rs.next(); System.out.println( "Value of fullAccessUsers is " + rs.getString(1)); // Confirm read-only users rs = s.executeQuery(getProperty + readOnlyAccessUsers + ")"); rs.next(); System.out.println( "Value of readOnlyAccessUsers is " + rs.getString(1)); // We would set the following property to TRUE only when we were // ready to deploy. Setting it to FALSE means that we can always // override using system properties if we accidentally paint // ourselves into a corner. s.executeUpdate("CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY(" + "'derby.database.propertiesOnly', 'false')"); s.close(); } /** * Report exceptions, with special handling of SQLExceptions, * and exit. * * @param e an exception (Throwable) */ static void errorPrintAndExit(Throwable e) { if (e instanceof SQLException) SQLExceptionPrint((SQLException)e); else { System.out.println("A non-SQL error occurred."); e.printStackTrace(); } System.exit(1); } /** * Iterate through a stack of SQLExceptions. * * @param sqle a SQLException */ static void SQLExceptionPrint(SQLException sqle) { while (sqle != null) { System.out.println("\n---SQLException Caught---\n"); System.out.println("SQLState: " + (sqle).getSQLState()); System.out.println("Severity: " + (sqle).getErrorCode()); System.out.println("Message: " + (sqle).getMessage()); sqle = sqle.getNextException(); } } }
import java.sql.*; public class AuthExampleClientSQLAuth2 { public static void main(String[] args) { String driver = "org.apache.derby.jdbc.ClientDriver"; String dbName="sqlAuthClientDB"; String dbOwner="mary"; String connectionURL = "jdbc:derby://localhost:1527/" + dbName; Connection conn = null; // Restart database and confirm that unauthorized users cannot // access it // Load the driver. This code is not needed if you are using // JDK 6, because in that environment the driver is loaded // automatically when the application requests a connection. try { Class.forName(driver); System.out.println(driver + " loaded."); } catch (java.lang.ClassNotFoundException ce) { System.err.print("ClassNotFoundException: "); System.err.println(ce.getMessage()); System.out.println("\n Make sure your CLASSPATH variable " + "contains %DERBY_HOME%\\lib\\derbyclient.jar " + "(${DERBY_HOME}/lib/derbyclient.jar). \n"); } catch (Exception ee) { errorPrintAndExit(ee); } // Try to log in with no username or password try { // connection attempt should fail System.out.println("Trying to connect to " + connectionURL + " without username or password"); conn = DriverManager.getConnection(connectionURL); System.out.println( "ERROR: Unexpectedly connected to database " + dbName); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("08004")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); } else { errorPrintAndExit(e); } } // Try to log in as a valid user with noAccess try { // connection attempt should fail String newURL = connectionURL + ";user=sa;password=ajaxj3x9"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println( "ERROR: Unexpectedly allowed to connect to database " + dbName); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("08004")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); } else { errorPrintAndExit(e); } } // Log in as a user with read-only access try { // connection should succeed, but create table should fail String newURL = connectionURL + ";user=guest;password=java5w6x"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName + " with read-only access"); Statement s = conn.createStatement(); s.executeUpdate( "CREATE TABLE accessibletbl(textcol VARCHAR(6))"); System.out.println( "ERROR: Unexpectedly allowed to modify database " + dbName); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("25503")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); try { conn.close(); } catch (SQLException ee) { errorPrintAndExit(ee); } } else { errorPrintAndExit(e); } } // Log in as a user with full access // Create, update, and query table // Grant select and insert privileges to another user try { // this should succeed String newURL = connectionURL + ";user=mary;password=little7xylamb"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName); Statement s = conn.createStatement(); s.executeUpdate( "CREATE TABLE accessibletbl(textcol VARCHAR(6))"); System.out.println("Created table accessibletbl"); s.executeUpdate("INSERT INTO accessibletbl VALUES('hello')"); ResultSet rs = s.executeQuery("SELECT * FROM accessibletbl"); rs.next(); System.out.println("Value of accessibletbl/textcol is " + rs.getString(1)); // grant insert privileges on table to user sqlsam s.executeUpdate( "GRANT SELECT, INSERT ON accessibletbl TO sqlsam"); System.out.println( "Granted select/insert privileges to sqlsam"); s.close(); conn.close(); } catch (SQLException e) { errorPrintAndExit(e); } // Log in as user with select and insert privileges on the table, // but not delete privileges try { String newURL = connectionURL + ";user=sqlsam;password=light8q9bulb"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName); // look at table Statement s = conn.createStatement(); ResultSet rs = s.executeQuery("SELECT * FROM mary.accessibletbl"); rs.next(); System.out.println("Value of accessibletbl/textcol is " + rs.getString(1)); s.executeUpdate( "INSERT INTO mary.accessibletbl VALUES('sam')"); System.out.println("Inserted string into table"); rs = s.executeQuery("SELECT * FROM mary.accessibletbl"); while (rs.next()) { System.out.println("Value of accessibletbl/textcol is " + rs.getString(1)); } s.close(); } catch (SQLException e) { errorPrintAndExit(e); } try { Statement s = conn.createStatement(); // this should fail s.executeUpdate("DELETE FROM mary.accessibletbl " + "WHERE textcol = 'hello'"); System.out.println("ERROR: Unexpectedly allowed to DELETE " + "table mary.accessibletbl"); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("42500")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); try { conn.close(); } catch (SQLException ee) { errorPrintAndExit(ee); } } else { errorPrintAndExit(e); } } /* Log in again as mary, delete table */ try { String newURL = connectionURL + ";user=mary;password=little7xylamb"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName); Statement s = conn.createStatement(); s.executeUpdate("DROP TABLE accessibletbl"); System.out.println("Removed table accessibletbl"); s.close(); } catch (SQLException e) { errorPrintAndExit(e); } try { cleanUpAndShutDown(conn); } catch (SQLException e) { errorPrintAndExit(e); } } /** Close connection and shut down database. * * @param conn a connection to the database */ public static void cleanUpAndShutDown (Connection conn) throws SQLException { String dbName="sqlAuthClientDB"; String dbOwner="mary"; String connectionURL = "jdbc:derby://localhost:1527/" + dbName; try { conn.close(); System.out.println("Closed connection"); // As mary, the database owner, shut down the database. try { String newURL = connectionURL + ";user=" + dbOwner + ";password=little7xylamb;shutdown=true"; DriverManager.getConnection(newURL); } catch (SQLException se) { if ( !se.getSQLState().equals("08006") ) { throw se; } } System.out.println("Database shut down normally"); } catch (SQLException e) { errorPrintAndExit(e); } } /** * Report exceptions, with special handling of SQLExceptions, * and exit. * * @param e an exception (Throwable) */ static void errorPrintAndExit(Throwable e) { if (e instanceof SQLException) SQLExceptionPrint((SQLException)e); else { System.out.println("A non-SQL error occurred."); e.printStackTrace(); } System.exit(1); } /** * Iterate through a stack of SQLExceptions. * * @param sqle a SQLException */ static void SQLExceptionPrint(SQLException sqle) { while (sqle != null) { System.out.println("\n---SQLException Caught---\n"); System.out.println("SQLState: " + (sqle).getSQLState()); System.out.println("Severity: " + (sqle).getErrorCode()); System.out.println("Message: " + (sqle).getMessage()); sqle = sqle.getNextException(); } } }
1.
| Starts Derby and creates
a database named sqlAuthEmbDB, using the embedded driver. The
connection URL creates the database as the user mary, who is
therefore the database owner. After SQL authorization is enabled, only the
database owner will have the right to set and read database properties. | |
2.
| Sets database properties that create users with different levels of access
(no access, read-only access, and full access), that require authentication, and
that turn on SQL authorization. The users mary and
sqlsam have full access. | |
3.
| Closes the connection, then stops and restarts the database so that the
authentication and SQL authorization changes can take effect. | |
4.
| Tries to connect to the database without a username and password, raising
an exception. | |
5.
| Tries to connect to the database as a user with no access, raising an
exception. | |
6.
| Connects to the database as a user with read-only access; the connection
succeeds, but an attempt to create a table raises an exception. | |
7.
| Connects to the database as mary, who has full access; this
user creates and populates a table. This user also grants select and insert
privileges on this table to another user. | |
8.
| Connects to the database as sqlsam, the user who has been
granted select and insert privileges by mary. This user has
full (that is, read-write) access on the connection level, but has limited
powers for this table because SQL authorization is active. The user successfully
performs select and insert operations on the table, but an attempt to delete a
row from the table raises an exception. | |
9.
| Connects to the database again as mary, who then deletes
the table. | |
10.
| Closes the connection, shuts down the database, then shuts down
Derby. |
import java.sql.*; public class AuthExampleEmbeddedSQLAuth { public static void main(String[] args) { String driver = "org.apache.derby.jdbc.EmbeddedDriver"; String dbName="sqlAuthEmbDB"; String dbOwner="mary"; String connectionURL = "jdbc:derby:" + dbName + ";user=" + dbOwner + ";create=true"; Connection conn = null; // Load the driver. This code is not needed if you are using // JDK 6, because in that environment the driver is loaded // automatically when the application requests a connection. try { Class.forName(driver); System.out.println(driver + " loaded."); } catch (java.lang.ClassNotFoundException ce) { System.err.print("ClassNotFoundException: "); System.err.println(ce.getMessage()); System.out.println("\n Make sure your CLASSPATH variable " + "contains %DERBY_HOME%\\lib\\derby.jar " + "(${DERBY_HOME}/lib/derby.jar).\n"); } catch (Exception ee) { errorPrintAndExit(ee); } // Create and boot the database as user mary (who then becomes // the database owner), set up users and then shut down the // database try { System.out.println("Trying to connect to " + connectionURL); conn = DriverManager.getConnection(connectionURL); System.out.println("Connected to database " + connectionURL); turnOnBuiltInUsers(conn); // Close connection conn.close(); System.out.println("Closed connection"); /* Shut down the database to make static properties take * effect. Because the default connection mode is now * noAccess, you must specify a user that has access. But * because requireAuthentication and sqlAuthorization do not * take effect until you restart the database, you do not * need to specify a password. * * Database shutdown throws the 08006 exception to confirm * success. */ try { DriverManager.getConnection("jdbc:derby:" + dbName + ";user=mary;shutdown=true"); } catch (SQLException se) { if ( !se.getSQLState().equals("08006") ) { throw se; } } System.out.println("Database shut down normally"); } catch (SQLException e) { errorPrintAndExit(e); } // Restart database and confirm that unauthorized users cannot // access it connectionURL = "jdbc:derby:" + dbName; // Try to log in with no username or password try { // connection attempt should fail System.out.println("Trying to connect to " + connectionURL + " without username or password"); conn = DriverManager.getConnection(connectionURL); System.out.println( "ERROR: Unexpectedly connected to database " + dbName); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("08004")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); } else { errorPrintAndExit(e); } } // Try to log in as a valid user with noAccess try { // connection attempt should fail String newURL = connectionURL + ";user=sa;password=ajaxj3x9"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println( "ERROR: Unexpectedly allowed to connect to database " + dbName); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("08004")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); } else { errorPrintAndExit(e); } } // Log in as a user with read-only access try { // connection should succeed, but create table should fail String newURL = connectionURL + ";user=guest;password=java5w6x"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName + " with read-only access"); Statement s = conn.createStatement(); s.executeUpdate( "CREATE TABLE accessibletbl(textcol VARCHAR(6))"); System.out.println( "ERROR: Unexpectedly allowed to modify database " + dbName); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("25503")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); try { conn.close(); } catch (SQLException ee) { errorPrintAndExit(ee); } } else { errorPrintAndExit(e); } } // Log in as a user with full access // Create, update, and query table // Grant select and insert privileges to another user try { // this should succeed String newURL = connectionURL + ";user=mary;password=little7xylamb"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName); Statement s = conn.createStatement(); s.executeUpdate( "CREATE TABLE accessibletbl(textcol VARCHAR(6))"); System.out.println("Created table accessibletbl"); s.executeUpdate("INSERT INTO accessibletbl VALUES('hello')"); ResultSet rs = s.executeQuery("SELECT * FROM accessibletbl"); rs.next(); System.out.println("Value of accessibletbl/textcol is " + rs.getString(1)); // grant insert privileges on table to user sqlsam s.executeUpdate( "GRANT SELECT, INSERT ON accessibletbl TO sqlsam"); System.out.println( "Granted select/insert privileges to sqlsam"); s.close(); conn.close(); } catch (SQLException e) { errorPrintAndExit(e); } // Log in as user with select and insert privileges on the table, // but not delete privileges try { String newURL = connectionURL + ";user=sqlsam;password=light8q9bulb"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName); // look at table Statement s = conn.createStatement(); ResultSet rs = s.executeQuery("SELECT * FROM mary.accessibletbl"); rs.next(); System.out.println("Value of accessibletbl/textcol is " + rs.getString(1)); s.executeUpdate( "INSERT INTO mary.accessibletbl VALUES('sam')"); System.out.println("Inserted string into table"); rs = s.executeQuery("SELECT * FROM mary.accessibletbl"); while (rs.next()) { System.out.println("Value of accessibletbl/textcol is " + rs.getString(1)); } s.close(); } catch (SQLException e) { errorPrintAndExit(e); } try { Statement s = conn.createStatement(); // this should fail s.executeUpdate("DELETE FROM mary.accessibletbl " + "WHERE textcol = 'hello'"); System.out.println("ERROR: Unexpectedly allowed to DELETE " + "table mary.accessibletbl"); cleanUpAndShutDown(conn); } catch (SQLException e) { if (e.getSQLState().equals("42500")) { System.out.println("Correct behavior: SQLException: " + e.getMessage()); try { conn.close(); } catch (SQLException ee) { errorPrintAndExit(ee); } } else { errorPrintAndExit(e); } } /* Log in again as mary, delete table */ try { String newURL = connectionURL + ";user=mary;password=little7xylamb"; System.out.println("Trying to connect to " + newURL); conn = DriverManager.getConnection(newURL); System.out.println("Connected to database " + dbName); Statement s = conn.createStatement(); s.executeUpdate("DROP TABLE accessibletbl"); System.out.println("Removed table accessibletbl"); s.close(); } catch (SQLException e) { errorPrintAndExit(e); } try { cleanUpAndShutDown(conn); } catch (SQLException e) { errorPrintAndExit(e); } } /** * Close connection and shut down database. Since this is embedded * mode, we must also shut down the Derby system. * * @param conn a connection to the database */ public static void cleanUpAndShutDown (Connection conn) throws SQLException { String dbName="sqlAuthEmbDB"; String dbOwner="mary"; String connectionURL = "jdbc:derby:" + dbName; try { conn.close(); System.out.println("Closed connection"); // As mary, the database owner, shut down the database. try { String newURL = connectionURL + ";user=" + dbOwner + ";password=little7xylamb;shutdown=true"; DriverManager.getConnection(newURL); } catch (SQLException se) { if ( !se.getSQLState().equals("08006") ) { throw se; } } System.out.println("Database shut down normally"); try { DriverManager.getConnection("jdbc:derby:;shutdown=true"); } catch (SQLException se) { if ( !se.getSQLState().equals("XJ015") ) { throw se; } } System.out.println("Derby system shut down normally"); } catch (SQLException e) { errorPrintAndExit(e); } } /** * Turn on built-in user authentication and SQL authorization. * * Default connection mode is fullAccess, but SQL authorization * restricts access to the owners of database objects. * * @param conn a connection to the database */ public static void turnOnBuiltInUsers(Connection conn) throws SQLException { String setProperty = "CALL SYSCS_UTIL.SYSCS_SET_DATABASE_PROPERTY("; String getProperty = "VALUES SYSCS_UTIL.SYSCS_GET_DATABASE_PROPERTY("; String requireAuth = "'derby.connection.requireAuthentication'"; String sqlAuthorization = "'derby.database.sqlAuthorization'"; String defaultConnMode = "'derby.database.defaultConnectionMode'"; String fullAccessUsers = "'derby.database.fullAccessUsers'"; String readOnlyAccessUsers = "'derby.database.readOnlyAccessUsers'"; String provider = "'derby.authentication.provider'"; String propertiesOnly = "'derby.database.propertiesOnly'"; System.out.println( "Turning on authentication and SQL authorization."); Statement s = conn.createStatement(); // Set requireAuthentication s.executeUpdate(setProperty + requireAuth + ", 'true')"); // Set sqlAuthorization s.executeUpdate(setProperty + sqlAuthorization + ", 'true')"); // Retrieve and display property values ResultSet rs = s.executeQuery(getProperty + requireAuth + ")"); rs.next(); System.out.println( "Value of requireAuthentication is " + rs.getString(1)); rs = s.executeQuery(getProperty + sqlAuthorization + ")"); rs.next(); System.out.println( "Value of sqlAuthorization is " + rs.getString(1)); // Set authentication scheme to Derby builtin s.executeUpdate(setProperty + provider + ", 'BUILTIN')"); // Create some sample users s.executeUpdate( setProperty + "'derby.user.sa', 'ajaxj3x9')"); s.executeUpdate( setProperty + "'derby.user.guest', 'java5w6x')"); s.executeUpdate( setProperty + "'derby.user.mary', 'little7xylamb')"); s.executeUpdate( setProperty + "'derby.user.sqlsam', 'light8q9bulb')"); // Define noAccess as default connection mode s.executeUpdate( setProperty + defaultConnMode + ", 'noAccess')"); // Confirm default connection mode rs = s.executeQuery(getProperty + defaultConnMode + ")"); rs.next(); System.out.println("Value of defaultConnectionMode is " + rs.getString(1)); // Define read-write users s.executeUpdate( setProperty + fullAccessUsers + ", 'sqlsam,mary')"); // Define read-only user s.executeUpdate( setProperty + readOnlyAccessUsers + ", 'guest')"); // Therefore, user sa has no access // Confirm full-access users rs = s.executeQuery(getProperty + fullAccessUsers + ")"); rs.next(); System.out.println( "Value of fullAccessUsers is " + rs.getString(1)); // Confirm read-only users rs = s.executeQuery(getProperty + readOnlyAccessUsers + ")"); rs.next(); System.out.println( "Value of readOnlyAccessUsers is " + rs.getString(1)); // We would set the following property to TRUE only when we were // ready to deploy. Setting it to FALSE means that we can always // override using system properties if we accidentally paint // ourselves into a corner. s.executeUpdate(setProperty + propertiesOnly + ", 'false')"); s.close(); } /** * Report exceptions, with special handling of SQLExceptions, * and exit. * * @param e an exception (Throwable) */ static void errorPrintAndExit(Throwable e) { if (e instanceof SQLException) SQLExceptionPrint((SQLException)e); else { System.out.println("A non-SQL error occurred."); e.printStackTrace(); } System.exit(1); } /** * Iterate through a stack of SQLExceptions. * * @param sqle a SQLException */ static void SQLExceptionPrint(SQLException sqle) { while (sqle != null) { System.out.println("\n---SQLException Caught---\n"); System.out.println("SQLState: " + (sqle).getSQLState()); System.out.println("Severity: " + (sqle).getErrorCode()); System.out.println("Message: " + (sqle).getMessage()); sqle = sqle.getNextException(); } } }
This allows the Derby engine complete access to the system directory and any databases contained in the system directory.permission java.io.FilePermission "${derby.system.home}/-", "read,write,delete";
/* Grants permission to run Derby and access all */ /* databases under the Derby system home */ /* when it is specified by the system property */ /* Derby.system.home */ /* Note Derby.system.home must be an absolute pathname */ grant codeBase "file://f:/derby/lib/derby.jar" { permission java.lang.RuntimePermission "createClassLoader"; permission java.util.PropertyPermission "derby.*", "read"; permission.java.io.FilePermission "${derby.system.home}","read"; permission java.io.FilePermission "${derby.system.home}${/} -", "read,write,delete"; permission java.util.PropertyPermission "derby.storage.jvmInstanceId", "write"; };
/* Grants permission to run Derby and access all */ /* databases under the Derby system home */ /* when it defaults to the current directory */ grant codeBase "file://f:/derby/lib/derby.jar" { permission java.lang.RuntimePermission "createClassLoader"; permission java.util.PropertyPermission "derby.*", "read"; permission java.util.PropertyPermission "user.dir", "read"; permission java.io.FilePermission "${derby.system.home}","read"; permission java.io.FilePermission "${user.dir}${/}-", "read,write,delete"; permission java.util.PropertyPermission "derby.storage.jvmInstanceId", "write"; };
/* Grants permission to run Derby and access a single */ /* database (salesdb) under the Derby system home */ /* Note Derby.system.home must be an absolute pathname */ grant codeBase "file://f:/derby/lib/derby.jar" { permission java.lang.RuntimePermission "createClassLoader"; permission java.util.PropertyPermission "derby.*", "read"; permission java.io.FilePermission "${derby.system.home}","read"; permission java.io.FilePermission "${derby.system.home}${/}*", "read,write,delete"; permission java.io.FilePermission "${derby.system.home}${/} salesdb${/}-", "read,write,delete"; permission java.util.PropertyPermission "derby.storage.jvmInstanceId", "write"; };
java.sql.DriverManager.getDriver( "jdbc:derby:").getPropertyInfo(URL, Prop)
• | name of the attribute | |
• | description | |
• | current value If an attribute has a default value, this is
set in the value field of DriverPropertyInfo, even if the attribute
has not been set in the connection URL or the Properties object.
If the attribute does not have a default value and it is not set in the URL
or the Properties object, its value will be null. | |
• | list of choices | |
• | whether required for a connection request |
import java.sql.*; import java.util.Properties; // start with the least amount of information // to see the full list of choices // we could also enter with a URL and Properties // provided by a user. String url = "jdbc:derby:"; Properties info = new Properties(); Driver cDriver = DriverManager.getDriver(url); for (;;) { DriverPropertyInfo[] attributes = cDriver.getPropertyInfo( url, info); // zero length means a connection attempt can be made if (attributes.length == 0) break; // insert code here to process the array, e.g., // display all options in a GUI and allow the user to // pick and then set the attributes in info or URL. } // try the connection Connection conn = DriverManager.getConnection(url, info);
• | You test an individual query or database connection and then try to run
an application that uses the same database as the tested feature. The
database connection established by testing the connection or query stays open,
and prevents the application from establishing a connection to the same database. | |
• | You run an application, and before it completes (for example, while it
waits for user input), you attempt to run a second application or to test
a connection or query that uses the same database as the first application. |
/* in java */ String myURL = conn.getMetaData().getURL();
SELECT phonebook.* FROM phonebook, (VALUES (CAST(? AS INT), CAST(? AS VARCHAR(255)))) AS Choice(choice, search_string) WHERE search_string = (case when choice = 1 then firstnme when choice=2 then lastname when choice=3 then phonenumber end);
CREATE TABLE MAPS ( MAP_ID INTEGER NOT NULL GENERATED ALWAYS AS IDENTITY (START WITH 1, INCREMENT BY 1), MAP_NAME VARCHAR(24) NOT NULL, REGION VARCHAR(26), AREA DECIMAL(8,4) NOT NULL, PHOTO_FORMAT VARCHAR(26) NOT NULL, PICTURE BLOB(102400), UNIQUE (MAP_ID, MAP_NAME) )
INSERT INTO OneColumnTable VALUES 1,2,3,4,5,6,7,8 INSERT INTO TwoColumnTable VALUES (1, 'first row'), (2, 'second row'), (3, 'third row')
ij> -- send 5 rows at a time: ij> PREPARE p1 AS 'INSERT INTO ThreeColumnTable VALUES (?,?,?), (?,?,?), (?,?,?), (?,?,?), (?,?,?)'; ij> EXECUTE p1 USING 'VALUES (''1st'',1,1,''2nd'',2,2,''3rd'', 3,3,''4th'',4,4,''5th'',5,5)';
-- get the names of all departments in OhioSELECT DeptName FROM Depts, (VALUES (1, 'Shoe'), (2, 'Laces'), (4, 'Polish')) AS DeptMap(DeptCode,DeptDesc) WHERE Depts.DeptCode = DeptMap.DeptCode AND Depts.DeptLocn LIKE '%Ohio%'
SELECT * FROM (VALUES ('',1,"TRUE")) AS ProcedureInfo(ProcedureName,NumParameters, ProcedureValid) WHERE 1=0
Example create commands | Collation is driven by |
jdbc:derby:abcDB;create=true | Unicode codepoint collation (UCS_BASIC), which is the
default collation for Derby databases. |
jdbc:derby:abcDB;create=true;territory=es_MX | Unicode codepoint collation (UCS_BASIC). The collation attribute
is not set. |
jdbc:derby:abcDB;create=true;collation=TERRITORY_BASED | The territory of the JVM, since the territory attribute
is not set. Tip: To determine the territory of the JVM, run Locale.getDefault(). |
jdbc:derby:abcDB;create=true;territory=es_MX;collation=TERRITORY_BASED | The territory attribute. |
orange | ||
apple | ||
Banana | ||
Pineapple | ||
Grape |
apple | ||
orange | ||
Banana | ||
Grape | ||
Pineapple |
apple | ||
Banana | ||
Grape | ||
orange | ||
Pineapple |
UCS_BASIC collation Territory-based collation Grape Grape Pineapple orange Pineapple
1.
| WHERE 'zcb' = 'xycb' | |
2.
| WHERE 'zcb' LIKE 'xy_b |
• | Database error messages are in the language of the locale, if support
is explicitly provided for that locale with a special library. For example, Derby explicitly supports Spanish-language
error messages. If a database's locale is set to one of the Spanish-language
locales, Derby returns
error messages in the Spanish language. | |
• | The Derby tools. In
the case of the tools, locale support includes locale-specific interface and
error messages and localized data display. For more information about
localization of the Derby tools,
see the Java DB Tools and Utilities Guide. |
• | You must have the locale-specific Derby jar
file. Derby provides such
jars for only some locales. You will find the locale jar files in the /lib
directory in your Derby installation. | |
• | The locale-specific Derby jar
file must be in the classpath. |
• | derbyLocale_cs.jar -
Czech | |
• | derbyLocale_de_DE.jar -
German | |
• | derbyLocale_es.jar
- Spanish | |
• | derbyLocale_fr.jar
- French | |
• | derbyLocale_hu.jar
- Hungarian | |
• | derbyLocale_it.jar
- Italian | |
• | derbyLocale_ja_JP.jar
- Japanese | |
• | derbyLocale_ko_KR.jar
- Korean | |
• | derbyLocale_pl.jar
- Polish | |
• | derbyLocale_pt_BR.jar
- Brazilian Portuguese | |
• | derbyLocale_ru.jar
- Russian | |
• | derbyLocale_zh_CN.jar
- Simplified Chinese | |
• | derbyLocale_zh_TW.jar
- Traditional Chinese |
• | GROUP BY clauses | |
• | ORDER BY clauses | |
• | JOIN operations | |
• | PRIMARY KEY constraints | |
• | Foreign KEY constraints | |
• | UNIQUE key constraints | |
• | MIN aggregate function | |
• | MAX aggregate function | |
• | [NOT] IN predicate | |
• | UNION, INTERSECT, and EXCEPT operators |
• | Use the XMLPARSE operator for binding data into XML values. | |
• | Use the XMLSERIALIZE operator to retrieve XML values from a result set. |
• | In most version 1.4.2 JVMs, the version of Xalan that comes with the JVM is
not new enough, so you must override the version of Xalan in the JVM with a
newer version by using the Endorsed Standards Override Mechanism described at
http://java.sun.com/j2se/1.4.2/docs/guide/standards/. To
use this mechanism, download and install a binary distribution of Xalan from
Apache and set the system property java.endorsed.dirs to point
to the Xalan installation directory. | |
• | In Sun JVMs later than version 1.4, Sun has renamed the JAXP packages so that
Derby cannot access them. If
you are using a Sun JVM later than version 1.4, download and install a binary
distribution of Xalan from Apache and place the xalan.jar file
in your classpath. The xalan.jar file automatically puts into
the classpath the other required jars that are in the same directory. |